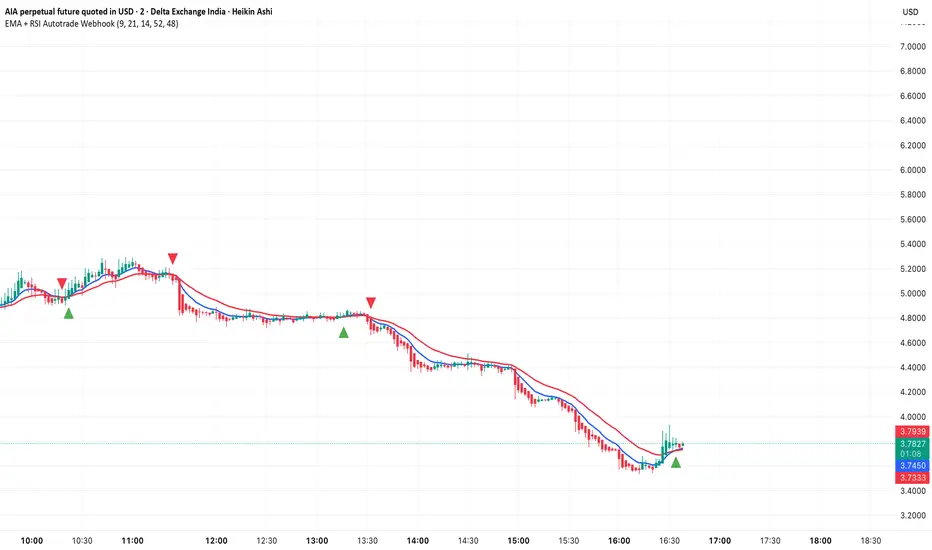
EMA + RSI Autotrade Webhook - VarunOverview
The EMA + RSI Autotrade Webhook is a powerful trend-following indicator designed for automated crypto futures trading. This indicator combines the reliability of Exponential Moving Average (EMA) crossovers with RSI momentum filtering to generate high-probability buy and sell signals optimized for webhook integration with crypto exchanges like Delta Exchange, Binance Futures, and Bybit.Key Features
Simple & Effective: Uses proven EMA 9/21 crossover strategy
RSI Momentum Filter: Eliminates low-probability trades in ranging markets
Webhook Ready: Two clean alerts (LONG Entry, SHORT Entry) for seamless automation
Exchange Compatible: Works with Delta Exchange, 3Commas, Alertatron, and other webhook platforms
Zero Lag Signals: Real-time alerts on crossover confirmation
Visual Clarity: Clean chart markers for easy signal identification
How It Works
Entry Signals:
LONG Entry: Triggers when EMA 9 crosses above EMA 21 AND RSI is above 52 (bullish momentum confirmed)
SHORT Entry: Triggers when EMA 9 crosses under EMA 21 AND RSI is below 48 (bearish momentum confirmed)
Technical Components:
Fast EMA: 9-period (tracks short-term price action)
Slow EMA: 21-period (identifies primary trend)
RSI: 14-period (confirms momentum strength)
RSI Long Threshold: 52 (filters weak bullish signals)
RSI Short Threshold: 48 (filters weak bearish signals)
Best Use Cases
Crypto Futures Trading: Bitcoin, Ethereum, Altcoin perpetual contracts
Automated Trading Bots: Integration with Delta Exchange webhooks, TradingView alerts
Timeframes: Optimized for 15-minute charts (works on 5min-1H)
Markets: Trending crypto markets with clear directional moves
Risk Management: Best used with 1-2% stop loss per trade (managed externally)
Webhook Automation Setup
Add indicator to your TradingView chart
Create alerts for "LONG Entry" and "SHORT Entry"
Configure webhook URL from your exchange (Delta Exchange, Binance, etc.)
Use alert message: Entry LONG {{ticker}} @ {{close}} or Entry SHORT {{ticker}} @ {{close}}
Exchange automatically reverses positions on opposite signals
Advantages
✅ No manual trading required - fully automated
✅ Eliminates emotional trading decisions
✅ Catches trending moves early with EMA crossovers
✅ RSI filter reduces whipsaws in choppy markets
✅ Works 24/7 without monitoring
✅ Simple two-alert system (easy to manage)
✅ Compatible with multiple exchanges via webhooksStrategy Philosophy
This indicator follows a trend-following with momentum confirmation approach. By waiting for both EMA crossover AND RSI confirmation, it ensures you're entering trades with genuine momentum behind them, not just random price noise. The tight RSI thresholds (52/48) keep you aligned with the prevailing trend.Recommended Settings
Timeframe: 15-minute (primary), 5-minute (scalping), 1-hour (swing)
Markets: BTC/USDT, ETH/USDT, high-liquidity altcoin perpetuals
Position Sizing: 100% capital per signal (exchange manages reversals)
Stop Loss: 2% (managed via exchange or external bot)
Leverage: 1-2x for conservative approach, up to 5x for aggressive
Important Notes
⚠️ This indicator generates entry signals only - position reversals are handled automatically by your exchange
⚠️ Always backtest on historical data before live trading
⚠️ Use proper risk management and position sizing
⚠️ Best performance in trending markets; may generate false signals in tight ranges
⚠️ Requires TradingView Premium or higher for webhook functionalityTags
cryptocurrency futures automated-trading ema-crossover rsi webhook delta-exchange tradingview-alerts trend-following momentum bitcoin ethereum crypto-bot algo-trading 15-minute-strategy
Search in scripts for "algo"
(Mustang Algo) Trend 5/15/30/1H + EMA Lines + Aligned Signal═══════════════════════════════════════════════════════════
MUSTANG ALGO - MULTI-TIMEFRAME TREND ALIGNMENT
═══════════════════════════════════════════════════════════
📊 OVERVIEW:
This indicator analyzes trend alignment across four key timeframes (5m, 15m, 30m, 1H) using customizable moving averages. It helps traders identify high-probability setups when multiple timeframes confirm the same trend direction.
🎯 KEY FEATURES:
✓ Multi-Timeframe Analysis (5m/15m/30m/1H)
- Monitors trend direction on 4 different timeframes simultaneously
- Visual table showing real-time trend status for each period
- Optional price display for each timeframe
✓ Flexible Moving Average System
- Choose from 5 MA types: EMA, SMA, SMMA (RMA), WMA, VWMA
- Customizable Fast MA (default: 20) and Slow MA (default: 50)
- Visual cloud between moving averages (green=bullish, red=bearish)
✓ Alignment Signals
- "4x UP" triangle: All 4 timeframes bullish (strong uptrend)
- "4x DOWN" triangle: All 4 timeframes bearish (strong downtrend)
- Signals appear only when ALL timeframes agree
✓ Visual Enhancements
- MA cloud with transparency for better chart readability
- Optional candle coloring based on local trend
- Clean, customizable dashboard display
✓ Alert System
- Built-in alerts for bullish alignment (4 TF aligned up)
- Built-in alerts for bearish alignment (4 TF aligned down)
- Perfect for automated trading setups
📈 HOW TO USE:
1. **Trend Confirmation**: Wait for alignment signals (triangles) before entering trades
2. **Dashboard Monitoring**: Check the top-right table to see individual TF trends
3. **MA Cloud**: Use the cloud as dynamic support/resistance
4. **Entry Timing**: Enter on local timeframe when higher TFs are aligned
⚙️ CUSTOMIZABLE PARAMETERS:
- Fast MA Length (default: 20)
- Slow MA Length (default: 50)
- MA Type (EMA/SMA/SMMA/WMA/VWMA)
- Toggle dashboard display
- Toggle price display in dashboard
- Toggle MA cloud
- Toggle candle coloring
⚠️ BEST PRACTICES:
- Use on 5m or 15m charts for optimal multi-TF analysis
- Combine with price action and volume for best results
- Alignment signals are rare but highly significant
- Not a standalone system - use as confluence tool
💡 STRATEGY IDEAS:
- Scalping: Enter on local TF when all TFs aligned
- Swing Trading: Hold positions while alignment maintained
- Risk Management: Exit if alignment breaks
- Confluence: Combine with support/resistance levels
📌 NOTES:
- Works on all markets (Crypto, Forex, Stocks, Indices)
- Repaints minimally (only on MA calculations)
- Low resource usage, efficient code
═══════════════════════════════════════════════════════════
Created by Mustang Spirit Trading Academy
For educational purposes - Always manage your risk!
═══════════════════════════════════════════════════════════
Institutional Compression Breakout (ICBO Algo) [@darshakssc]The ICBO Algo is a smart intraday trading tool that detects institutional compression zones followed by breakout confirmation. It combines candle range analysis, volume compression, EMA filtering, and ATR-based Risk/Reward zones to highlight high-probability trade setups with visual clarity.
This script is designed for educational and research purposes only, fully aligned with TradingView’s Pine Script policy and publishing guidelines.
🔍 Key Features
🌀 Compression Zone Detection
Identifies low-range, low-volume candles often formed before institutional breakouts.
📈📉 Breakout Signals
Triggered after confirmed price + EMA breakout post-compression.
📊 Dashboard Panel
Displays breakout phase, current R:R ratio, and zone status in real-time.
🟢🔴 Buy/Sell Labels with Emojis
Clean and non-intrusive labels for immediate action recognition.
🔔 Alerts Included
Receive real-time push, email, or webhook alerts for breakout signals.
⚙️ How It Works
Compression Phase:
When the candle range and volume are significantly lower than the moving average, the script flags it as a compression zone.
Breakout Confirmation:
A breakout signal is confirmed when the price breaks the previous high/low and is above/below the trend EMA.
Entry Logic:
📈 Buy: Price > previous high + above EMA after compression
📉 Sell: Price < previous low + below EMA after compression
⚠️ Disclaimer
This script is intended for educational and research purposes only. It does not constitute financial advice or recommendations of any kind. Always use proper risk management. Past performance does not guarantee future results.

[Mustang Algo] Channel Strategy# Mustang Algo Channel Strategy - Universal Market Sentiment Oscillator
## 🎯 ORIGINAL CONCEPT
This strategy employs a unique market sentiment oscillator that works on ALL financial assets. It uses Bitcoin supply dynamics combined with stablecoin market capitalization as a macro sentiment indicator to generate universal timing signals across stocks, forex, commodities, indices, and cryptocurrencies.
## 🌐 UNIVERSAL APPLICATION
- **Any Asset Class:** Stocks, Forex, Commodities, Indices, Crypto, Bonds
- **Market-Wide Timing:** BTC/Stablecoin ratio serves as a global risk sentiment gauge
- **Cross-Market Signals:** Trade any instrument using macro liquidity conditions
- **Ecosystem Approach:** One oscillator for all financial markets
## 🧮 METHODOLOGY
**Core Calculation:** BTC Supply / (Combined Stablecoin Market Cap / BTC Price)
- **Data Sources:** DAI + USDT + USDC market capitalizations
- **Signal Generation:** RSI(14) applied to the ratio, double-smoothed with WMA
- **Timing Logic:** Crossover signals filtered by overbought/oversold zones
- **Multi-Timeframe:** Configurable timeframe analysis (default: Daily)
## 📈 TRADING STRATEGY
**LONG Entries:** Bullish crossover when market sentiment is oversold (<48)
**SHORT Entries:** Bearish crossover when market sentiment is overbought (>55)
**Universal Timing:** These macro signals apply to trading any financial instrument
## ⚙️ FLEXIBLE RISK MANAGEMENT
**Three SL/TP Calculation Modes:**
- **Percentage Mode:** Traditional % based (4% SL, 12% TP default)
- **Ticks Mode:** Precise tick-based calculation (50/150 ticks default)
- **Pips Mode:** Forex-style pip calculation (50/150 pips default)
**Realistic Parameters:**
- Commission: 0.1% (adjustable for different asset classes)
- Slippage: 2 ticks
- Position sizing: 10% of equity (conservative)
- No pyramiding (single position management)
## 📊 KEY ADVANTAGES
✅ **Universal Application:** One strategy for all asset classes
✅ **Macro Foundation:** Based on global liquidity and risk sentiment
✅ **False Signal Filtering:** Overbought/oversold zones reduce noise
✅ **Flexible Risk Management:** Multiple SL/TP calculation methods
✅ **No Lookahead Bias:** Clean backtesting with realistic results
✅ **Cross-Market Correlation:** Captures broad market risk cycles
## 🎛️ CONFIGURATION GUIDE
1. **Asset Selection:** Apply to stocks, forex, commodities, indices, crypto
2. **Timeframe Setup:** Daily recommended for swing trading
3. **Sentiment Bounds:** Adjust 48/55 levels based on market volatility
4. **Risk Management:** Choose appropriate SL/TP mode for your asset class
5. **Direction Filter:** Select Long Only, Short Only, or Both
## 📋 BACKTESTING STANDARDS
**Compliant with TradingView Guidelines:**
- ✅ Realistic commission structure (0.1% default)
- ✅ Appropriate slippage modeling (2 ticks)
- ✅ Conservative position sizing (10% equity)
- ✅ Sustainable risk ratios (1:3 SL/TP)
- ✅ No lookahead bias (proper historical simulation)
- ✅ Sufficient sample size potential (100+ trades possible)
## 🔬 ORIGINAL RESEARCH
This strategy introduces a revolutionary approach to financial markets by treating the BTC/Stablecoin ratio as a global risk sentiment gauge. Unlike traditional indicators that analyze individual asset price action, this oscillator captures macro liquidity flows that affect ALL financial markets - from stocks to forex to commodities.
## 🎯 MARKET APPLICATIONS
**Stocks & Indices:** Risk-on/risk-off sentiment timing
**Forex:** Global liquidity flow analysis for major pairs
**Commodities:** Risk appetite for inflation hedges
**Bonds:** Flight-to-safety vs. risk-seeking behavior
**Crypto:** Native application with direct correlation
## ⚠️ RISK DISCLOSURE
- Designed for intermediate to long-term trading across all timeframes
- Market sentiment can remain extreme longer than expected
- Always use appropriate position sizing for your specific asset class
- Adjust commission and slippage settings for different markets
- Past performance does not guarantee future results
## 🚀 INNOVATION SUMMARY
**What makes this strategy unique:**
- First to use BTC/Stablecoin ratio as universal market sentiment indicator
- Applies macro-economic principles to technical analysis across all assets
- Single oscillator provides timing signals for entire financial ecosystem
- Bridges traditional finance with digital asset insights
- Combines fundamental liquidity analysis with technical precision
Daily Single Trade [SMRT Algo]The Daily Single Trade Indicator by SMRT Algo is a powerful yet simple tool designed for traders who value precision, discipline, and a focus on high-quality trade setups. With a unique approach, this indicator identifies just one signal daily, making it ideal for traders who prefer a structured and stress-free trading routine.
Please note that this indicator only works for timeframes below 1H.
Key Features:
Market Open & Pre-Market Analysis: The indicator focuses on the market’s opening range and identifies breakout opportunities based on price action during these critical periods.
Customizable Risk-Reward Ratio: Plan your trades with precision by setting your desired RR, ensuring that your take-profit (TP) levels are multiples of your stop-loss (SL). Stop loss is not shown with this indicator.
Price Offset for SL: Add a customizable buffer to your SL and TP levels. This offset accounts for market volatility, reducing the chances of premature stop-outs while maintaining alignment with your trading plan.
Increasing this value will lead to a greater invisible stop loss, which will increase the TP size. The opposite is occurs when decreasing this value (less than 0). If you set it as 2.5 for example for TSLA: price is 340 and SL is 330 for example, SL becomes 327.5. This calculation will then be applied to calculate the TP.
In simple terms, if the offset is positive, SL becomes larger, TP becomes larger as well.
Exit Point Visibility: Display exit points on your chart to better visualize trade targets and stop levels.
Adjustable Market Open Time: Easily modify the market open hour and minute to suit your asset’s trading session. For example, U.S. stock traders can set the market open time to 9:30 AM EST (UTC-5).
By providing a single signal each day, the indicator minimizes overtrading and keeps your focus on the best opportunities.
With predefined SL, TP, and RR settings, the indicator fosters disciplined trading, reducing the influence of emotional decision-making. Whether you’re trading stocks, indices, or forex, the customizable market open time and RR ratio make this indicator versatile and adaptable.
The combination of precise SL and TP calculations with offset pip adjustments helps protect your trades from market noise while maintaining a favorable RR.
Perfect for those who can’t monitor markets all day, the single-signal approach allows you to execute a high-quality trade and move on with your day.
How to Use:
Set the Market Open Time: Adjust the open time to align with your asset’s session. For example, set 9:30 AM EST for U.S. stocks.
Define Your Risk-Reward Ratio: Choose an RR multiple (e.g., 1:2 or 1:3) that aligns with your risk tolerance and trading goals.
Apply Pip Offset: Add a buffer to your SL and TP to account for market volatility and reduce false stops.
The Daily Single Trade Indicator simplifies trading by focusing on one high-probability setup per day. It’s perfect for traders looking to maintain consistency, improve risk management, and reduce the stress of overanalyzing the markets.
How Alerts Work:
Individual Alerts: Set separate notifications for specific actions, such as breakout signals, take-profit levels, or stop-loss activations.
Master Alert: Manage all notifications with one streamlined setting, ensuring you never miss an opportunity while keeping your setup simple and efficient.
Take control of your trading with a strategy built for clarity, precision, and success!

Harish Algo 2The script "Harish Algo 2" is a Pine Script-based TradingView indicator that automatically identifies significant trendlines based on fractal points and tracks price interactions with those trendlines. Key features include:
Fractal Detection: The script identifies fractal highs and lows, using a configurable fractal period, to serve as pivot points for generating trendlines. Fractal highs are marked in blue, and fractal lows are marked in red.
Dynamic Trendlines: It draws trendlines between consecutive fractal points, with a limit on the maximum number of active trendlines. The trendlines can be extended either in both directions or to the right, as per user input. The line width can also be customized.
Support/Resistance Counting: Each trendline tracks how many times the price interacts with it. If the price approaches the line from above and touches or stays near it, the line is considered a support. If the price approaches from below, it is considered a resistance. These counts are used to modify the trendline's color and appearance.
Trendlines with 2 support interactions turn green.
Trendlines with 2 resistance interactions turn red.
Trendlines with 3 or more interactions turn black.
Trendline Styling: Trendlines that extend over a long period (more than 100 bars) change to a dotted style to highlight their persistence.
Break Detection: The script monitors if the price crosses a trendline, signaling a potential breakout or breakdown. Once a trendline is broken, it stops extending further.
Trendline Removal: The script ensures that only a limited number of trendlines are active at a time. If the maximum number of trendlines is reached, the oldest trendline is removed to make space for new ones.
This indicator is designed to help traders visualize important trendlines, spot potential support and resistance levels, and detect breakouts or breakdowns based on price movement.

DTFX Algo Zones [LuxAlgo]DTFX Algo Zones are auto-generated Fibonacci Retracements based on market structure shifts.
These retracement levels are intended to be used as support and resistance levels to look for price to bounce off of to confirm direction.
🔶 USAGE
Due to the retracement levels only being generated from identified market structure shifts, the retracements are confined to only draw from areas considered more important due to the technical Break of Structure (BOS) or Change of Character (CHoCH).
The simple action that causes a market structure shift occurs is price breaking above or below a specific swing point. When a market structure shift happens, a retracement is drawn from the point of break to the highest or lowest point since that point. Due to the price action necessary for a market structure shift, these retracements will not always be immediately actionable.
These retracement levels are intended to be used as points to watch for price to retrace to and bounce from, confirming the current direction of price.
In the example below, after the retracement is initiated, by bouncing off of the retracement levels formed from the previous market structure shift it would further confirm the bias of the market structure shift. A break going through these levels would display a weakness from the current market structure shift, implying that it could simply be noise.
🔶 DETAILS
The script uses standard SMC Market structure identification to determine Break of Structures (BOS) and Change of Characters (CHoCH). The specific swing points can be identified by the shapes placed above or below the specific swing high/low candle.
By unchecking the "Display All Zones" setting, users are able to specify the exact number of retracement zones to display using the "Show Last" parameter. This is handy for cleaning up the chart to stay focused on the most recent retracements.
Additionally, when displaying multiple zones, the "Clean-Up Level Overlap" setting may be helpful for decluttering as well. This option optimizes the display of retracement levels to minimize their overlap on other adjacent zones.
The script allows for up to 5 Fib levels to be displayed from each zone, with options for display, value, line style, and color for each of the 5.
The calculation for Fib Levels changes depending on the direction of market structure shifts. When an upwards (Bullish) zone is generated, the retracement is drawn with the bottom of the zone being 0 and the top of the zone being 1. This is reversed for downwards (Bearish) zones.
🔶 SETTINGS
Structure Length: Sets the SMC structure length to use for finding MMS.
Show Last: Displays this number of retracement zones. (Display All Zones Must be Unchecked)
Display All Zones: Ignores "Show Last" number and displays all historical MMS Retracement Zones.
Zone Display: Choose which zones to display, only bearish, only bullish, or both.
Clean-Up Level Overlap: Minimizes overlap between adjacent zones and levels.
Fib Levels: Settings to display and customize up to 5 Fib levels for each zone.

EHRHART Algo Premium (V.2)EHRHART Algo Premium is a indicator designed to help traders analyze market flow. It work with multiple EMA for identifying the sentiment of market. It's very simple calculation but it's a good help for people who use price action. I think the visual of the chart is very important and and I wanted to create an indicator very visual. I'm price action lover like lots of people and I personally think it's very important to identify the flow of market because buying when the flow of market is up give you better chance to win your trade. It's not BUY and SELL signal, this indicator don't tell u when u need buy or when u need sell, it's principally here for helping the visual of trading chart (have a good clear chart). I decided to post this indicator because people were asking me how it worked and were curious about these colors, so here we go !
This indicator show:
The main flow ( green candle=buy pressure /red candle=seller pressure ), it's based on two EMA cross over, this two EMA are editable so u can take the combination you want depending on your trading strategy. When the first EMA is above the second EMA candle becoming green and when the second EMA is above the first EMA candle becoming red.
The trend of two EMA crossover (blue=bullish and violet=bearish), it's based on two EMA (two different than main flow) cross over, this two EMA are editable so u can take the combination you want depending on your trading strategy. When the first EMA is above the second EMA the trend becoming blue and when the second EMA is above the first EMA the trend becoming violet.
Potential trend reversals (violet candle), it's calculate with the two EMA of the main flow, when these two EMA becoming closer, the candle becoming violet. It meaning that the trend may reversals. I added sensitivity parameter, so u can adjust it depending on your trading strategy, the more sensitive it is, the more candle will be colored violet.
A system of RSI print on the chart, when the RSI becoming overbought (more than 75) a red triangle will pop up on the chart, and when the RSI becoming oversold (less than 25) a green triangle will pop up on the chart. U can show or hidden these setting.
Bullish candles are represented by hollow candles.
Bearish candles are represented by full candles.
You can use this indicator with multiple strategy, I personally use it with price action (support/resistance) and I made it for that (but it's your choice).
This is an example of how I'll use it:
Here we can see that the price is coming testing our weakly support, however the main flow is bullish (red candle), so I'm waiting my first signal (violet candle). When the first candle passed violet I decided to enter the trade because violet candle after red candle means that the two EMA start closed to themselves meaning that's the flow may turn green. My second signal will be candle passed green, because it meaning the two EMA start deviate from themselves, buyer are taking advantage. In this situation a green triangle on the support will be my third signal.
Candlestick Patterns [NAS Algo]Candlestick Patterns plots most commonly used chart patterns to help and understand the market structure.
Bullish Reversal Patterns:
Hammer:
Appearance: Small body near the high, long lower shadow.
Interpretation: Indicates potential bullish reversal after a downtrend.
Inverted Hammer:
Appearance: Small body near the low, long upper shadow.
Interpretation: Signals potential bullish reversal, especially when the preceding trend is bearish.
Three White Soldiers:
Appearance: Three consecutive long bullish candles with higher closes.
Interpretation: Suggests a strong reversal of a downtrend.
Bullish Harami:
Appearance: Small candle (body) within the range of the previous large bearish candle.
Interpretation: Implies potential bullish reversal.
Bearish Reversal Patterns:
Hanging Man:
Appearance: Small body near the high, long lower shadow.
Interpretation: Suggests potential bearish reversal after an uptrend.
Shooting Star:
Appearance: Small body near the low, long upper shadow.
Interpretation: Indicates potential bearish reversal, especially after an uptrend.
Three Black Crows:
Appearance: Three consecutive long bearish candles with lower closes.
Interpretation: Signals a strong reversal of an uptrend.
Bearish Harami:
Appearance: Small candle (body) within the range of the previous large bullish candle.
Interpretation: Implies potential bearish reversal.
Dark Cloud Cover:
Appearance: Bearish reversal pattern where a bullish candle is followed by a bearish candle that opens above the high of the previous candle and closes below its midpoint.
Continuation Patterns:
Rising Three Methods:
Appearance: Consists of a long bullish candle followed by three small bearish candles and another bullish candle.
Interpretation: Indicates the continuation of an uptrend.
Falling Three Methods:
Appearance: Consists of a long bearish candle followed by three small bullish candles and another bearish candle.
Interpretation: Suggests the continuation of a downtrend.
Gravestone Doji:
Appearance: Doji candle with a long upper shadow, little or no lower shadow, and an opening/closing price near the low.
Interpretation: Signals potential reversal, particularly in an uptrend.
Long-Legged Doji:
Appearance: Doji with long upper and lower shadows and a small real body.
Interpretation: Indicates indecision in the market and potential reversal.
Dragonfly Doji:
Appearance: Doji with a long lower shadow and little or no upper shadow.
Interpretation: Suggests potential reversal, especially in a downtrend.

ICT Clean Midnight [dR-Algo]
Are you a trader who values clean charts and precise indicators? Are you an avid follower of ICT Concepts? If so, the Midnight Marker is tailored for you. This ultra-simple, highly effective TradingView script draws a nearly transparent blue line at midnight on your chart, keeping your interface as clean as possible while delivering essential information.
Why is "ICT Clean Midnight" so Special?
Focus on Price Action: The minimalist design ensures that you can focus solely on price action, which is a core principle of ICT teachings.
Easy Back Testing: Whether you're trading live or back-testing strategies, the midnight marker helps you quickly identify key time points.
Customizable: Though designed to be subtle, the line's color and opacity can be easily customized to suit your charting needs.
This indicator embodies ICT's principle of maintaining a clutter-free, focus-driven trading environment. Perfect for both novice traders wanting to adopt ICT concepts and seasoned traders looking for minimalistic yet effective tools.

Bjorgum Double Tap█ OVERVIEW
Double Tap is a pattern recognition script aimed at detecting Double Tops and Double Bottoms. Double Tap can be applied to the broker emulator to observe historical results, run as a trading bot for live trade alerts in real time with entry signals, take profit, and stop orders, or to simply detect patterns.
█ CONCEPTS
How Is A Pattern Defined?
Doubles are technical formations that are both reversal patterns and breakout patterns. These formations typically have a distinctive “M” or a “W” shape with price action breaking beyond the neckline formed by the center of the pattern. They can be recognized when a pivot fails to break when tested for a second time and the retracement that follows breaks beyond the key level opposite. This can trap entrants that were playing in the direction of the prior trend. Entries are made on the breakout with a target projected beyond the neckline equal to the height of the pattern.
Pattern Recognition
Patterns are recognized through the use of zig-zag; a method of filtering price action by connecting swing highs and lows in an alternating fashion to establish trend, support and resistance, or derive shapes from price action. The script looks for the highest or lowest point in a given number of bars and updates a list with the values as they form. If the levels are exceeded, the values are updated. If the direction changes and a new significant point is made, a new point is added to the list and the process starts again. Meanwhile, we scan the list of values looking for the distinctive shape to form as previously described.
█ STRATEGY RESULTS
Back Testing
Historical back testing is the most common method to test a strategy due in part to the general ease of gathering quick results. The underlying theory is that any strategy that worked well in the past is likely to work well in the future, and conversely, any strategy that performed poorly in the past is likely to perform poorly in the future. It is easy to poke holes in this theory, however, as for one to accept it as gospel, one would have to assume that future results will match what has come to pass. The randomness of markets may see to it otherwise, so it is important to scrutinize results. Some commonly used methods are to compare to other markets or benchmarks, perform statistical analysis on the results over many iterations and on differing datasets, walk-forward testing, out-of-sample analysis, or a variety of other techniques. There are many ways to interpret the results, so it is important to do research and gain knowledge in the field prior to taking meaningful conclusions from them.
👉 In short, it would be naive to place trust in one good backtest and expect positive results to continue. For this reason, results have been omitted from this publication.
Repainting
Repainting is simply the difference in behaviour of a strategy in real time vs the results calculated on the historical dataset. The strategy, by default, will wait for confirmed signals and is thus designed to not repaint. Waiting for bar close for entires aligns results in the real time data feed to those calculated on historical bars, which contain far less data. By doing this we align the behaviour of the strategy on the 2 data types, which brings significance to the calculated results. To override this behaviour and introduce repainting one can select "Recalculate on every tick" from the properties tab. It is important to note that by doing this alerts may not align with results seen in the strategy tester when the chart is reloaded, and thus to do so is to forgo backtesting and restricts a strategy to forward testing only.
👉 It is possible to use this script as an indicator as opposed to a full strategy by disabling "Use Strategy" in the "Inputs" tab. Basic alerts for detection will be sent when patterns are detected as opposed to complex order syntax. For alerts mid-bar enable "Recalculate on every tick" , and for confirmed signals ensure it is disabled.
█ EXIT ORDERS
Limit and Stop Orders
By default, the strategy will place a stop loss at the invalidation point of the pattern. This point is beyond the pattern high in the case of Double Tops, or beneath the pattern low in the case of Double Bottoms. The target or take profit point is an equal-legs measurement, or 100% of the pattern height in the direction of the pattern bias. Both the stop and the limit level can be adjusted from the user menu as a percentage of the pattern height.
Trailing Stops
Optional from the menu is the implementation of an ATR based trailing stop. The trailing stop is designed to begin when the target projection is reached. From there, the script looks back a user-defined number of bars for the highest or lowest point +/- the ATR value. For tighter stops the user can look back a lesser number of bars, or decrease the ATR multiple. When using either Alertatron or Trading Connector, each change in the trail value will trigger an alert to update the stop order on the exchange to reflect the new trail price. This reduces latency and slippage that can occur when relying on alerts only as real exchange orders fill faster and remain in place in the event of a disruption in communication between your strategy and the exchange, which ensures a higher level of safety.
👉 It is important to note that in the case the trailing stop is enabled, limit orders are excluded from the exit criteria. Rather, the point in time that the limit value is exceeded is the point that the trail begins. As such, this method will exit by stop loss only.
█ ALERTS
Five Built-in 3rd Party Destinations
The following are five options for delivering alerts from Double Tap to live trade execution via third party API solutions or chat bots to share your trades on social media. These destinations can be selected from the input menu and alert syntax will automatically configure in alerts appropriately to manage trades.
Custom JSON
JSON, or JavaScript Object Notation, is a readable format for structuring data. It is used primarily to transmit data between a server and a web application. In regards to this script, this may be a custom intermediary web application designed to catch alerts and interface with an exchange API. The JSON message is a trade map for an application to read equipped with where its been, where its going, targets, stops, quantity; a full diagnostic of the current state and its previous state. A web application could be configured to follow the messages sent in this format and conduct trades in sync with alerts running on the TV server.
Below is an example of a rendered JSON alert:
{
"passphrase": "1234",
"time": "2022-05-01T17:50:05Z",
"ticker": "ETHUSDTPERP",
"plot": {
"stop_price": 2600.15,
"limit_price": 3100.45
},
"strategy": {
"position_size": 0.1,
"order_action": "buy",
"market_position": "long",
"market_position_size": 0,
"prev_market_position": "flat",
"prev_market_position_size": 0
}
}
Trading Connector
Trading Connector is a third party fully autonomous Chrome extension designed to catch alert webhooks from TradingView and interface with MT4/MT5 to execute live trades from your machine. Alerts to Trading Connector are simple; just select the destination from the input drop down menu, set your ticker in the "TC Ticker" box in the "Alert Strings" section and enter your URL in the alert window when configuring your alert.
Alertatron
Alertatron is an automated algo platform for cryptocurrency trading that is designed to automate your trading strategies. Although the platform is currently restricted to crypto, it offers a versatile interface with high flexibility syntax for complex market orders and conditions. To direct alerts to Alertatron, select the platform from the 3rd party drop down, configure your API key in the ”Alertatron Key” box and add your URL in the alert message box when making alerts.
3 Commas
3 Commas is an easy and quick to use click-and-go third party crypto API solution. Alerts are simple without overly complex syntax. Messages are simply pasted into alerts and executed as alerts are triggered. There are 4 boxes at the bottom of the "Inputs" tab where the appropriate messages to be placed. These messages can be copied from 3 Commas after the bots are set up and pasted directly into the settings menu. Remember to select 3 Commas as a destination from the third party drop down and place the appropriate URL in the alert message window.
Discord
Some may wish to share their trades with their friends in a Discord chat via webhook chat bot. Messages are configured to notify of the pattern type with targets and stop values. A bot can be configured through the integration menu in a Discord chat to which you have appropriate access. Select Discord from the 3rd party drop down menu and place your chat bot URL in the alert message window when configuring alerts.
👉 For further information regarding alert setup, refer to the platform specific instructions given by the chosen third party provider.
█ IMPORTANT NOTES
Setting Alerts
For alert messages to be properly delivered on order fills it is necessary to place the following placeholder in the alert message box when creating an alert.
{{strategy.order.alert_message}}
This placeholder will auto-populate the alert message with the appropriate syntax that is designated for the 3rd party selected in the user menu.
Order Sizing and Commissions
The values that are sent in alert messages are populated from live metrics calculated by the strategy. This means that the actual values in the "Properties" tab are used and must be set by the user. The initial capital, order size, commission, etc. are all used in the calculations, so it is important to set these prior to executing live trades. Be sure to set the commission to the values used by the exchange as well.
👉 It is important to understand that the calculations on the account size take place from the beginning of the price history of the strategy. This means that if historical results have inflated or depleted the account size from the beginning of trade history until now, the values sent in alerts will reflect the calculated size based on the inputs in the "Properties" tab. To start fresh, the user must set the date in the "Inputs" tab to the current date as to remove trades from the trade history. Failure to follow this instruction can result in an unexpected order size being sent in the alert.
█ FOR PINECODERS
• With the recent introduction of matrices in Pine, the script utilizes a matrix to track pivot points with the bars they occurred on, while tracking if that pivot has been traded against to prevent duplicate detections after a trade is exited.
• Alert messages are populated with placeholders ; capability that previously was only possible in alertcondition() , but has recently been extended to `strategy.*()` functions for use in the `alert_message` argument. This allows delivery of live trade values to populate in strategy alert messages.
• New arguments have been added to strategy.exit() , which allow differentiated messages to be sent based on whether the exit occurred at the stop or the limit. The new arguments used in this script are `alert_profit` and `alert_loss` to send messages to Discord

Bittrex ALT Index v0.0.3 @PEQUET - Trex Shalts by FA Algo Scoreusing the top 10 FA algo names via coincheckup.com

Absolute Momentum Indicator Covered intensevely by Gary Antonnacci in his paper " Absolute Momentum : A simple Rule Based Strategy and Universal Trend Following Overlay , Absolute momentum buys asset with excess return, which is calculated by taking the return of the asset for a giving period of time LESS the Treasury bill rate . The following indicator is based on the rules found in the paper. However you have the liberty to choose your time frame and symbol to calculate the excess return .
Read more about this indicator here
Cheers
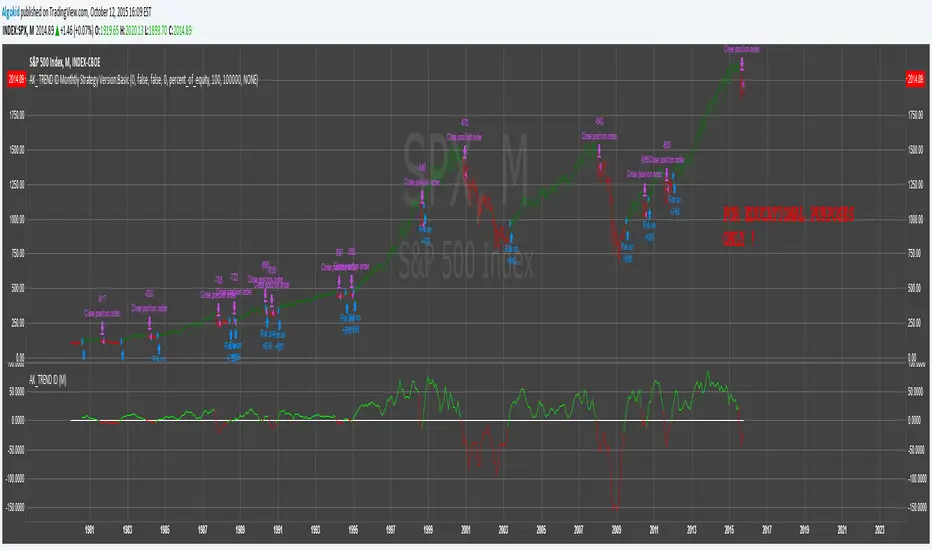
AK_ TREND ID AS A STRATEGY : FOR EDUCATIONAL PURPOSES ONLYJust converted the AK_ TREND ID into a strategy , to show the efficiency of this simple indicator. I used SPX in this example, to display that the indicator has been accurate for a long time.


3SPC Three Candle Price Action Setup3SPC (Three Candle Price Action Setup) is an open-source indicator designed to detect
a simple and clearly defined three-candle price action pattern.
The logic is based on the following structure:
• The first two candles move in the same direction (bullish or bearish).
• The third candle interacts with the real bodies of both previous candles,
which may indicate a short-term liquidity sweep or price reaction.
• A bullish setup is confirmed when price holds above the open of the first candle.
• A bearish setup is confirmed when price holds below the open of the first candle.
This script does not use oscillators or lagging indicators.
It is intended as a visual aid for discretionary traders and should be used
together with market context, risk management and higher timeframe analysis.
The script is published as open-source for educational and transparency purposes.
UI Labels Translation:
- نمایش ستاپ صعودی: Show bullish setups
- نمایش ستاپ نزولی: Show bearish setups

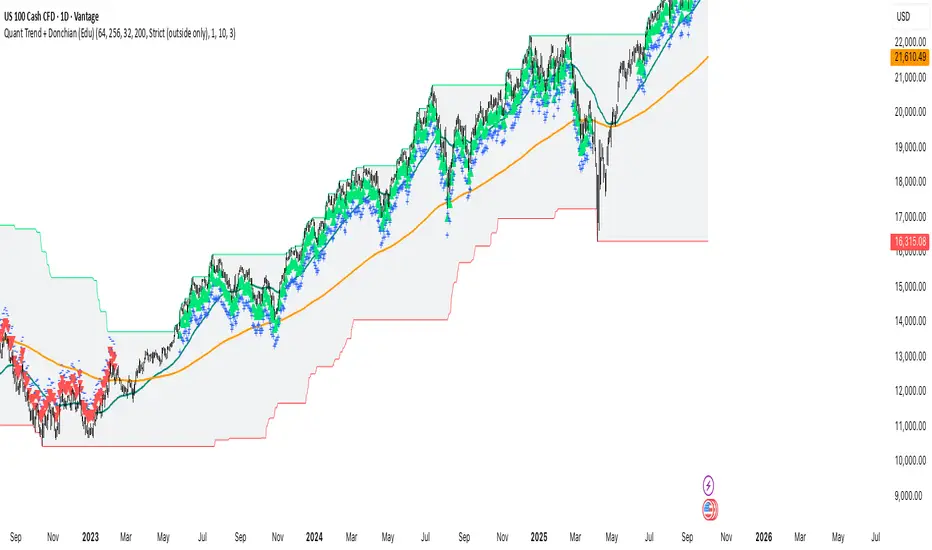
Quant Trend + Donchian (Educational, Public-Safe)What this does
Educational, public-safe visualization of a quant regime model:
• Trend : EMA(64) vs EMA(256) (EWMAC proxy)
• Breakout : Donchian channel (200)
• Volatility-awareness : internal z-scores (not plotted) for concept clarity
Why it’s useful
• Shows when trend & breakout align (clean regimes) vs conflict (chop)
• Helps explain why volatility-aware systems size up in smooth trends and scale down in noise
How to read it
• EMA64 above EMA256 with price near/above Donchian high → trend-following alignment
• EMA64 below EMA256 with price near/below Donchian low → bearish alignment
• Inside channel with EMAs tangled → range/chop risk
Notes
• Indicator is educational only (no orders).
• Built entirely with TradingView built-ins.
• For consistent visuals: enable “Indicator values on price scale” and disable “Scale price chart only” in Settings → Scales .
Historical AverageThis indicator calculates the sum of all past candles for each new candle.
For the second candle of the chart, the indicator shows the average of the first two candles. For the 10th candle, it's the average of the last ten candles.
Simple Moving Averages (SMAa) calculate the average of a specific timeframe (e.g. SMA200 for the last 200 candles). The historical moving average is an SMA 2 at the second candle, an SMA3 for the third candle, an SMA10 for the tenth, an SMA200 for the 200th candle etc.
Settings:
You can set the multiplier to move the Historical Moving Average along the price axis.
You can show two Historical Moving Averages with different multipliers.
You can add fibonacci multipliers to the Historical Moving Average.
This indicator works best on charts with a lot of historical data.
Recommended charts:
INDEX:BTCUSD
BLX
But you can use it e.g. on DJI or any other chart as well.
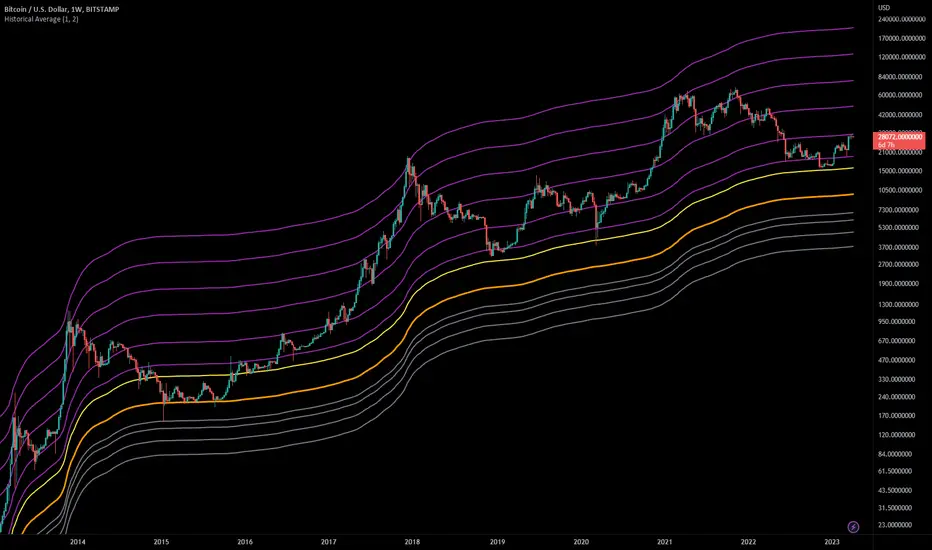
Super Trend LineThe classic and simple Super Trend Line. Enjoy it and have a nice trading
Hashtag_binary ;D
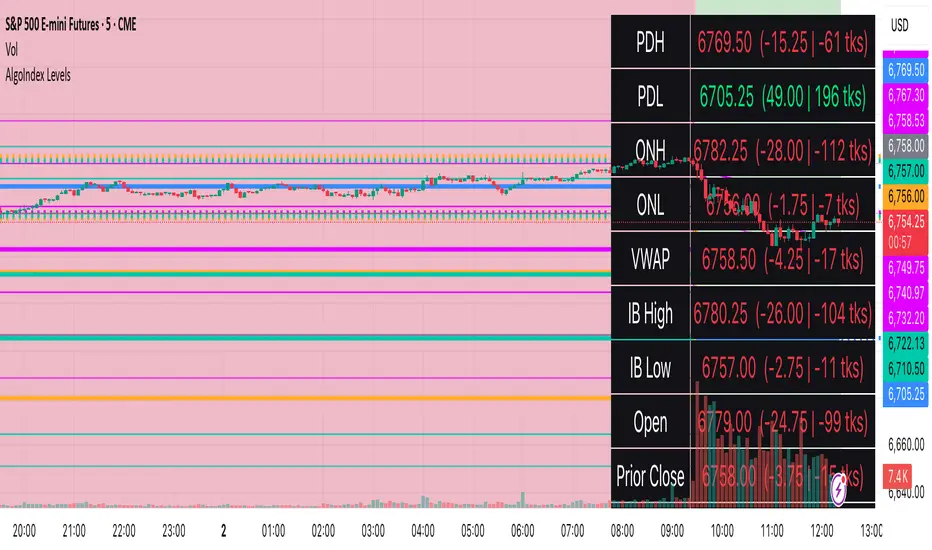
RTH Levels: VWAP + PDH/PDL + ONH/ONL + IBAlgo Index — Levels Pro (ONH/ONL • PDH/PDL • VWAP±Bands • IB • Gaps)
Purpose. A session-aware, non-repainting levels tool for intraday decision-making. Designed for futures and indices, with clean visuals, alerts, and a one-click Minimal Mode for screenshot-ready charts.
What it plots
• PDH/PDL (RTH-only) – Prior Regular Trading Hours high/low, computed intraday and frozen at the RTH close (no 24h mix-ups, no repainting).
• ONH/ONL – Prior Overnight high/low, held throughout RTH.
• RTH VWAP with ±σ bands – Volume-weighted variance, reset each RTH.
• Initial Balance (IB) – First N minutes of RTH, plus 1.5× / 2.0× extensions after IB completes.
• Today’s RTH Open & Prior RTH Close – With gap detection and “gap filled” alert.
• Killzone shading – NY Open (09:30–10:30 ET) and Lunch (11:15–13:30 ET).
• Values panel (top-right) – Each level with live distance in points & ticks.
• Right-edge level tags – With anti-overlap (stagger + vertical jitter).
• Price-scale tags – Native trackprice markers that always “stick” to the axis.
⸻
New in v6.4
• Minimal Mode: one click for a clean look (thinner lines, VWAP bands/IB extensions hidden, on-chart right-edge labels off; price-scale tags remain).
• Theme presets: Dark Hi-Contrast / Light Minimal / Futures Classic / Muted Dark.
• Anti-overlap controls: horizontal staggering, vertical jitter, and baseline offset to keep tags readable even when levels cluster.
⸻
Quick start (2 minutes)
1. Add to chart → keep defaults.
2. Sessions (ET):
• RTH Session default: 09:30–16:00 (US equities cash hours).
• Overnight Session default: 18:00–09:29.
Adjust for your market if you use different “day” hours (e.g., many use 08:20–13:30 ET for COMEX Gold).
3. Theme & Minimal Mode: pick a Theme Preset; enable Minimal Mode for screenshots.
4. Visibility: toggle PD/ON/VWAP/IB/References/Panel to taste.
5. Right-edge labels: turn Show Right-Edge Labels on. If they crowd, tune:
• Anti-overlap: min separation (ticks)
• Horizontal offset per tag (bars)
• Vertical jitter per step (ticks)
• Right-edge baseline offset (bars)
6. Alerts: open Add alert → Condition: and pick the events you want.
⸻
How levels are computed (no repainting)
• PDH/PDL: Intraday H/L are accumulated only while in RTH and saved at RTH close for “yesterday’s” values.
• ONH/ONL: Accumulated across the defined Overnight window and then held during RTH.
• RTH VWAP & ±σ: Volume-weighted mean and standard deviation, reset at the RTH open.
• IB: First N minutes of RTH (default 60). Extensions (1.5×/2.0×) appear after IB completes.
• Gaps: Today’s RTH open vs prior RTH close; “Gap Filled” triggers when price trades back to prior close.
⸻
Practical playbooks (how to trade around the levels)
1) PDH/PDL interactions
• Rejection: Price taps PDH/PDL then closes back inside → mean-reversion toward VWAP/IB.
• Acceptance: Close/hold beyond PDH/PDL with momentum → continuation to next HTF/IB target.
• Alert: PD Touch/Break.
2) ONH/ONL “taken”
• Often one ON extreme is taken during RTH. ONH Taken / ONL Taken → check if it’s a clean break or sweep & reclaim.
• Sweep + reclaim near VWAP can fuel rotations through the ON range.
3) VWAP ±σ framework
• Balanced: First tag of ±1σ often reverts toward VWAP.
• Trend: Persistent trade beyond ±1σ + IB break → target ±2σ/±3σ.
• Alerts: VWAP Cross and VWAP Reject (cross then immediate fail back).
4) IB breaks
• After IB completes, a clean IB break commonly targets 1.5× and sometimes 2.0×.
• Quick return inside IB = possible fade back to the opposite IB edge/VWAP.
• Alerts: IB Break Up / Down.
5) Gaps
• Gap-and-go: Opening drive away from prior close + VWAP support → trend until IB completion.
• Gap-fill: Weak open and VWAP overhead/underfoot → trade toward prior close; manage on Gap Filled alert.
Pro tip: Stack confluences (e.g., ONL sweep + VWAP reclaim + IB hold) and respect your execution rules (e.g., require a 5-minute close in direction, or your order-flow confirmation).
⸻
Inputs you’ll actually touch
• Sessions (ET): Session Timezone, RTH Session, Overnight Session.
• Visibility: toggles for PD/ON/VWAP/IB/Ref/Panel.
• VWAP bands: set σ multipliers (±1/±2/±3).
• IB: duration (minutes) and extension multipliers (1.5× / 2.0×).
• Style & Theme: Theme Preset, Main Line Width, Trackprice, Minimal Mode, and anti-overlap controls.
⸻
Alerts included
• PD Touch/Break — High ≥ PDH or Low ≤ PDL
• ONH Taken / ONL Taken — First in-RTH take of ONH/ONL
• VWAP Cross — Close crosses VWAP
• VWAP Reject — Cross then immediate fail back
• IB Break Up / Down — Break of IB High/Low after IB completes
• Gap Filled — Price trades back to prior RTH close
Setup: Add alert → Condition: Algo Index — Levels Pro → choose event → message → Notify on app/email.
⸻
Panel guide
The top-right panel shows each level plus live distance from last price:
LevelValue (Δpoints | Δticks)
Coloring: green if level is below current price, red if above.
⸻
Styling & screenshot tips
• Use Theme Preset that matches your chart.
• For dark charts, “Dark Hi-Contrast” with Main Line Width = 3 works well.
• Enable Trackprice for crisp axis tags that always stick to the right edge.
• Turn on Minimal Mode for cleaner screenshots (no VWAP bands or IB extensions, on-chart tags off; price-scale tags remain).
• If tags crowd, increase min separation (ticks) to 30–60 and horizontal offset to 3–5; add vertical jitter (4–12 ticks) and/or push tags farther right with baseline offset (bars).
⸻
Behavior & limitations
• Levels are computed incrementally; tables refresh on the last bar for efficiency.
• Right-edge labels are placed at bar_index + offset and do not track extra right-margin scrolling (TradingView limitation). The price-scale tags (from trackprice) do track the axis.
• “RTH” is what you define in inputs. If your market uses different day hours, change the session strings so PDH/PDL reflect your definition of “yesterday’s session.”
⸻
FAQ
Q: My PDH/PDL don’t match the daily chart.
A: By design this uses RTH-only highs/lows, not 24h daily bars. Adjust sessions if you want a different definition.
Q: Right-edge tags overlap or don’t sit at the far right.
A: Increase min separation / horizontal offset / vertical jitter and/or push tags farther with baseline offset. If you want markers that always hug the axis, rely on Trackprice.
Q: Can I change killzones?
A: Yes—edit the session strings in settings or request a version with user inputs for custom windows.
⸻
Disclaimer
Educational use only. This is not financial advice. Always apply your own risk management and confirmation rules.
⸻
Enjoy it? Please ⭐ the script and share screenshots using Minimal Mode + a Theme Preset that fits your style.
Algo ۞ Halo 7MAs WonderA complete trend following and important MA crossing tool.
The indicator is self-explanatory. You decide where you want the triggers to go.
Enjoy!
