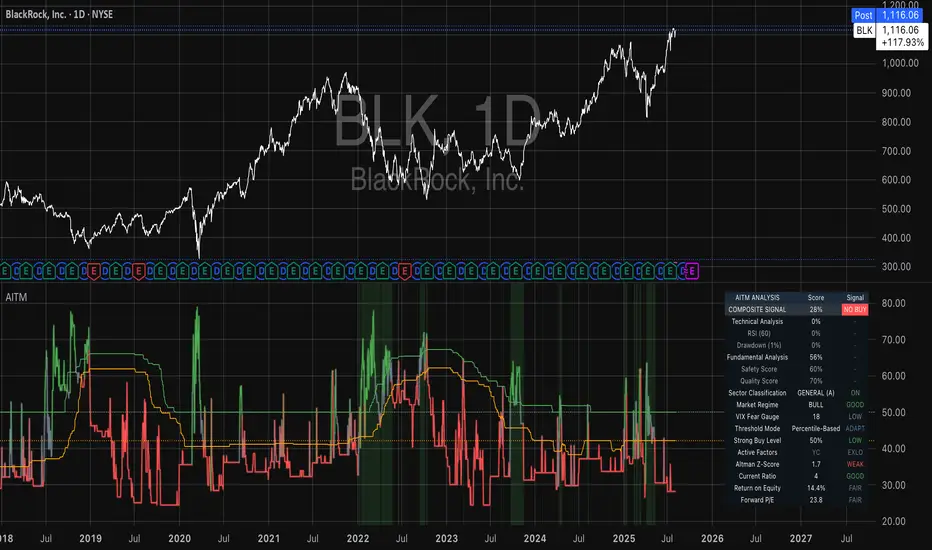
Recession Warning Traffic LightThis is an indicator that uses 6 different metrics to determine the combined probability of a recession and compares the high probability warning periods against actual historical periods of recession.
GREEN tells us that the referenced recession indicators are not exhibiting any warning. Observe the long stretches of “all-green” in between recessionary periods in the chart above.
RED will show a full-on warning level for that particular recession indicator, signaling that monitoring of this sector is clearly showing a problem – which has in the past, reliably exhibited itself as a forewarning of recessions.
Adding green and red together can help determine a combined probability of recession.
IMPORTANT: Your chart should be on 1d and set to SPX , DJI ,or NDQ indices
Precious metals: This indicator calculates the relative prices of Gold & rhodium. Gold is a flight-to-quality asset. Rhodium is the rarest of precious industrial metals and prices spike when the economy is heating up. In front of a recession, the upper relative movement of rhodium precedes gold.
Stock markets: This indicator compares closing prices to growth rate curves of the SPX. This indication is the noisiest but tells us very well when the recession has ended. Stock market indices, which respond to “smart money” moving out of markets when the other indicators begin to warn of recession, or when markets become overheated and rise to historically unsustainable levels.
Yield curve: This indicator compares the 3m & 10y treasuries and detects yield curve inversions. Interest rates are controlled by the Federal Reserve and by the purchasers in the Federal Treasury auction markets, which together create the treasury yield curve. This inversion is the most reliable recession indicator. These happen during a flight to quality.
Federal Reserve: This indicator measures GDP and detects contraction which is technically a recession. This is usually one of the last indicators to enter a Warning state, and it could be 6 months delayed simply confirming what may have already been projected.
Money Supply. This indicator measures the M2 money supply, which typically grows about 1% per calendar quarter. When this shrinks, it's tapping the brakes on the economy. This can also lead to yield curve inversion. This is also a measure of inflation and its effects on the aggregate money supply (liquid capital) available for short-term economic activity, or which can be directed into the purchase of long-term, less liquid assets.
Leading Economic factors: There is a whole basket of leading economic indicators that, as collections, reflect overall growth or contraction of economic activity. These indicators include measures of level and growth in productivity, employment, housing, consumer confidence, industrial purchasing confidence, and much more. These indicators may or may not be detached from the broader economy, and often provide up to 6 months of foresight. For more information please visit www.conference-board.org
Actual Recession: Central Bank indicators are published by the Federal Reserve and reflect their own analysis of national and regional economic health, as well as their calculations of the likelihood of a recession. The Federal Reserve has a recession ticker which is used to plot periods of actual recessions on this indicator for comparison.
Pine Script® indicator