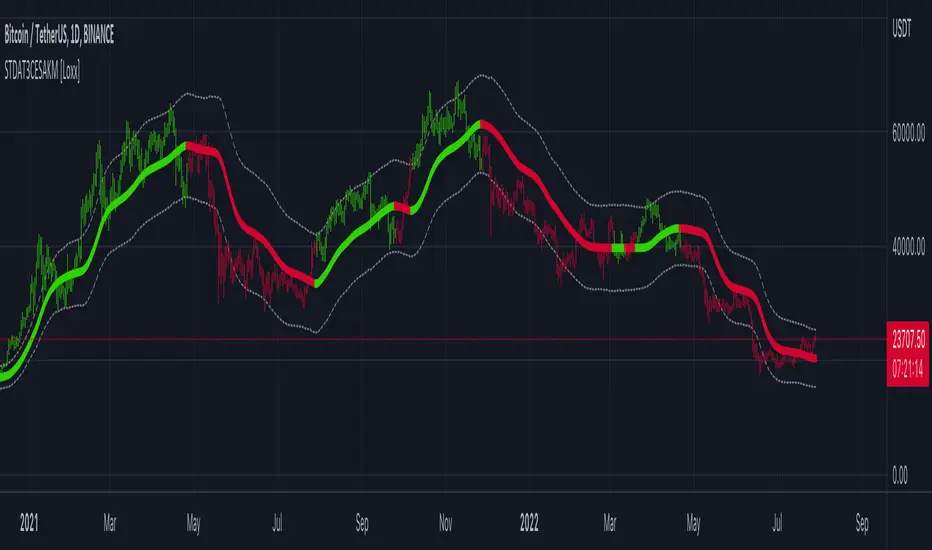
STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. [Loxx]STD-Adaptive T3 Channel w/ Ehlers Swiss Army Knife Mod. is an adaptive T3 indicator using standard deviation adaptivity and Ehlers Swiss Army Knife indicator to adjust the alpha value of the T3 calculation. This helps identify trends and reduce noise. In addition. I've included a Keltner Channel to show reversal/exhaustion zones.
What is the Swiss Army Knife Indicator?
John Ehlers explains the calculation here: www.mesasoftware.com
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Search in scripts for "11月1日是什么星座"
T3 Velocity [Loxx]T3 Velocity is a simple velocity indicator using T3 moving average that uses gradient colors to better identify trends.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

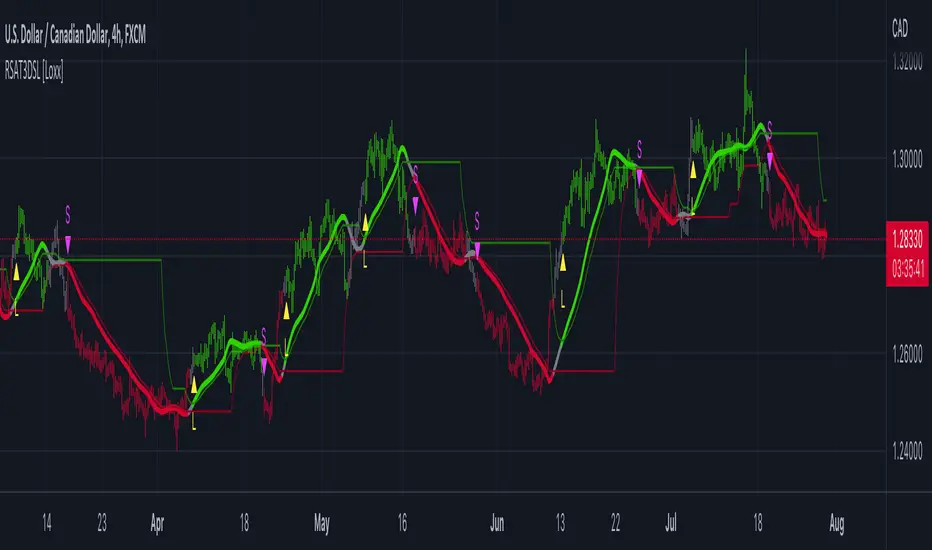
R-squared Adaptive T3 w/ DSL [Loxx]R-squared Adaptive T3 w/ DSL is the following T3 indicator but with Discontinued Signal Lines added to reduce noise and thereby increase signal accuracy. This adaptation makes this indicator lower TF scalp friendly.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
EMA and FEMA Signla/DSL smoothing
Loxx's Expanded Source Types
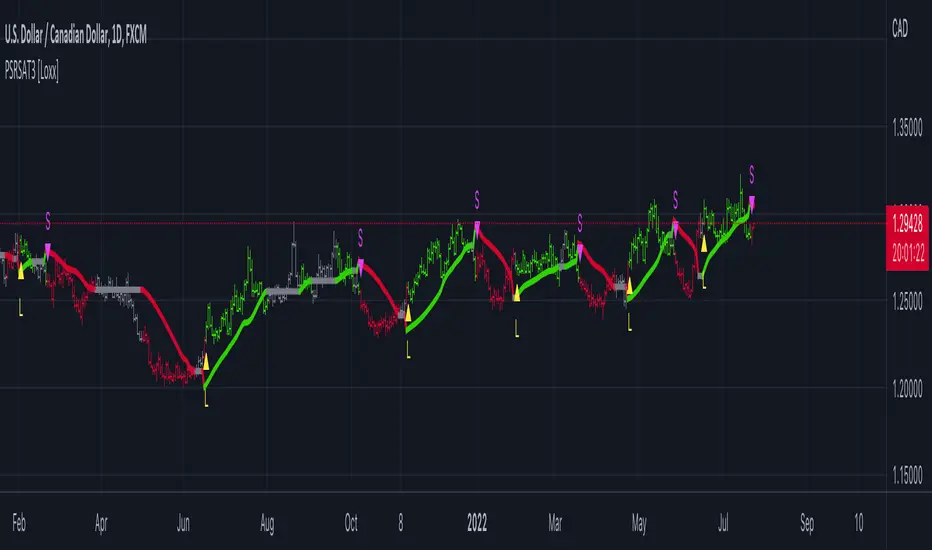
STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones [Loxx]STD-Filterd, R-squared Adaptive T3 w/ Dynamic Zones is a standard deviation filtered R-squared Adaptive T3 moving average with dynamic zones.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
What are Dynamic Zones?
As explained in "Stocks & Commodities V15:7 (306-310): Dynamic Zones by Leo Zamansky, Ph .D., and David Stendahl"
Most indicators use a fixed zone for buy and sell signals. Here’ s a concept based on zones that are responsive to past levels of the indicator.
One approach to active investing employs the use of oscillators to exploit tradable market trends. This investing style follows a very simple form of logic: Enter the market only when an oscillator has moved far above or below traditional trading lev- els. However, these oscillator- driven systems lack the ability to evolve with the market because they use fixed buy and sell zones. Traders typically use one set of buy and sell zones for a bull market and substantially different zones for a bear market. And therein lies the problem.
Once traders begin introducing their market opinions into trading equations, by changing the zones, they negate the system’s mechanical nature. The objective is to have a system automatically define its own buy and sell zones and thereby profitably trade in any market — bull or bear. Dynamic zones offer a solution to the problem of fixed buy and sell zones for any oscillator-driven system.
An indicator’s extreme levels can be quantified using statistical methods. These extreme levels are calculated for a certain period and serve as the buy and sell zones for a trading system. The repetition of this statistical process for every value of the indicator creates values that become the dynamic zones. The zones are calculated in such a way that the probability of the indicator value rising above, or falling below, the dynamic zones is equal to a given probability input set by the trader.
To better understand dynamic zones, let's first describe them mathematically and then explain their use. The dynamic zones definition:
Find V such that:
For dynamic zone buy: P{X <= V}=P1
For dynamic zone sell: P{X >= V}=P2
where P1 and P2 are the probabilities set by the trader, X is the value of the indicator for the selected period and V represents the value of the dynamic zone.
The probability input P1 and P2 can be adjusted by the trader to encompass as much or as little data as the trader would like. The smaller the probability, the fewer data values above and below the dynamic zones. This translates into a wider range between the buy and sell zones. If a 10% probability is used for P1 and P2, only those data values that make up the top 10% and bottom 10% for an indicator are used in the construction of the zones. Of the values, 80% will fall between the two extreme levels. Because dynamic zone levels are penetrated so infrequently, when this happens, traders know that the market has truly moved into overbought or oversold territory.
Calculating the Dynamic Zones
The algorithm for the dynamic zones is a series of steps. First, decide the value of the lookback period t. Next, decide the value of the probability Pbuy for buy zone and value of the probability Psell for the sell zone.
For i=1, to the last lookback period, build the distribution f(x) of the price during the lookback period i. Then find the value Vi1 such that the probability of the price less than or equal to Vi1 during the lookback period i is equal to Pbuy. Find the value Vi2 such that the probability of the price greater or equal to Vi2 during the lookback period i is equal to Psell. The sequence of Vi1 for all periods gives the buy zone. The sequence of Vi2 for all periods gives the sell zone.
In the algorithm description, we have: Build the distribution f(x) of the price during the lookback period i. The distribution here is empirical namely, how many times a given value of x appeared during the lookback period. The problem is to find such x that the probability of a price being greater or equal to x will be equal to a probability selected by the user. Probability is the area under the distribution curve. The task is to find such value of x that the area under the distribution curve to the right of x will be equal to the probability selected by the user. That x is the dynamic zone.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types

Pips-Stepped, R-squared Adaptive T3 [Loxx]Pips-Stepped, R-squared Adaptive T3 is a a T3 moving average with optional adaptivity, trend following, and pip-stepping. This indicator also uses optional flat coloring to determine chops zones. This indicator is R-squared adaptive. This is also an experimental indicator.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination (R-squared), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average.
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Bar coloring
Signals
Alerts
Flat coloring
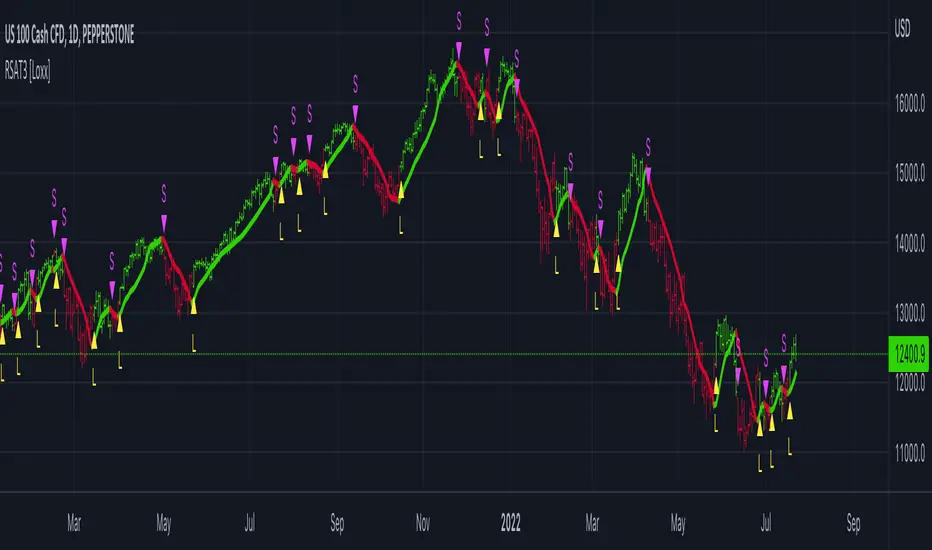
R-squared Adaptive T3 [Loxx]R-squared Adaptive T3 is an R-squared adaptive version of Tilson's T3 moving average. This adaptivity was originally proposed by mladen on various forex forums. This is considered experimental but shows how to use r-squared adapting methods to moving averages. In theory, the T3 is a six-pole non-linear Kalman filter.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis. Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD, Momentum, Relative Strength Index) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA (simple moving average) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA(n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA.
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE/2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE/2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE/2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA, popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE/2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA(3) has lag 1, and EMA(11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA(3) through itself 5 times than if I just take EMA(11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA(3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA(7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA(n) = EMA(n) + EMA(time series - EMA(n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA. The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA(n) + EMA(time series - EMA(n))*.7;
This is algebraically the same as:
EMA(n)*1.7-EMA(EMA(n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD(n,v) = EMA(n)*(1+v)-EMA(EMA(n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA, and when v=1, GD is DEMA. In between, GD is a cooler DEMA. By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD(GD(GD(n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA(n)) to correct themselves. In Technical Analysis, these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
Loxx's Expanded Source Types
Short Swing Bearish MACD Cross (By Coinrule)This strategy is oriented towards shorting during downside moves, whilst ensuring the asset is trading in a higher timeframe downtrend, and exiting after further downside.
This script can work well on coins you are planning to hodl for long-term and works especially well whilst using an automated bot that can execute your trades for you. It allows you to hedge your investment by allocating a % of your coins to trade with, whilst not risking your entire holding. This mitigates unrealised losses from hodling as it provides additional cash from the profits made. You can then choose to hodl this cash, or use it to reinvest when the market reaches attractive buying levels. Alternatively, you can use this when trading contracts on futures markets where there is no need to already own the underlying asset prior to shorting it.
ENTRY
This script utilises the MACD indicator accompanied by the Exponential Moving Average (EMA) 450 to enter trades. The MACD is a trend following momentum indicator and provides identification of short-term trend direction. In this variation it utilises the 11-period as the fast and 26-period as the slow length EMAs, with signal smoothing set at 9.
The EMA 450 is used as additional confirmation to prevent the script from shorting when price is above this long-term moving average. Once price is above the EMA 450 the script will not open any shorts - preventing the rule from attempting to short uptrends. Due to this, this strategy is ideal for setting and forgetting.
The script will enter trades based on two conditions:
1) When the MACD signals a bearish cross. This occurs when the EMA 11 crosses below the EMA 26 within the MACD signalling the start of a potential downtrend.
2) Price has closed below the EMA 450. Price closing below this long-term EMA signals that the asset is in a sustained downtrend. Price breaking above this could indicate a bullish strength in which shorting would not be profitable.
EXIT
This script utilises a set take-profit and stop-loss from the entry of the trade. The take profit is set at 8% and the stop loss of 4%, providing a risk reward ratio of 2. This indicates the script will be profitable if it has a win ratio greater than 33%.
Take-Profit Exit: -8% price decrease from entry price.
OR
Stop-Loss Exit: +4% price increase from entry price.
Based on backtesting results across a selection of assets, the 45-minute and 1-hour timeframes are the best for this strategy.
The strategy assumes each order is using 30% of the available coins to make the results more realistic and to simulate you only ran this strategy on 30% of your holdings. A trading fee of 0.1% is also taken into account and is aligned to the base fee applied on Binance.
The backtesting data was recorded from December 1st 2021, just as the market was beginning its downtrend. We therefore recommend analysing the market conditions prior to utilising this strategy as it operates best on weak coins during downtrends and bearish conditions, however the EMA 450 condition should mitigate entries during bullish market conditions.

OpenCipher AOpenCipher A is an open-source and free to use Overlay.
Features:
EMA Ribbons (Lengths: 5, 11, 15, 18, 21, 25, 29, 33)
Symbols ("Be careful" and "attention required" signals)
EMA Ribbons
The EMA RIbbons are a set of exponential moving averages. Blue and white ribbons = uptrend, gray ribbons = downtrend. The ribbons can act as support in uptrends and as resistance in downtrends.
Lengths and source of the ribbons are customizable.
Symbols
Green Dots: The green dot is a bullish symbol that appears whenever the EMA 11 crosses over EMA 33.
Red Cross: The red cross is a bearish symbol that appears whenever the EMA 5 crosses under EMA 11.
Blue Triangle: The blue triangle marks a possible trend reversal that appears whenever the EMA 5 crosses over EMA 25 while EMA 29 is below EMA 33.
Red Diamond: The red diamond is a bearish symbol that marks a potential local top whenever a bearish wavecross occurs (fast wave crosses under slow wave).
Yellow X: The yellow X is a warning signal that appears whenever a bearish wavecross occurs while the slow wave of the wavetrend is below -40 and the moneyflow is in the red (below zero).
Blood Diamond: The blood diamond is a bearish symbol that highlights whenever the red diamond and the red cross appear on the same candle.
Usage
Treat the symbols as signs that your attention might be required and don't trade based on them.

Ema Crosses nklassEs un simple indicador de cruces con EMAs, de 11, 22, 50 y 200 periodos.
En un intervalo de velas diarias se obtienen las mejores señales, pero funciona bien para 4h y 15min tambien, recomiendo operar con los cruces de mayor probabilidad por encima y por debajo de la ema200, por debajo solo entradas en CORTO, y por encima solo entradas en Largo, luego de una señal se puede obtener un mejor Riesgo Beneficio si se espera a un posible test del ema 50, y se entra luego de un cierre de vela por por fuera de la ema 11, dandote un buen punto para el stop loss. Recomiendo utilizarlo basandose en zonas de soporte y resistencia de marcos temporales mas altos y teniendo en cuenta posibles divergencias en RSI al igual que su posicion en el momento de entrar al mercado.

Runners & Laggers (scanner)Firstly, seems to me this may only work with crypto but I know nothing about the other sectors so i could be wrong. I was trying to think up a good way to find moving coins(other than by volume bc theres holes in the results when using it this way). Thought this was an interesting concept so decided to publish it as I've seen no others like it (though i did not extensively search for it. We need to start with a little Tradingview(TV) common knowledge. When there is no update of trades/volume in a candle TV does not print the candle. So when looking at (let's say) a 1 second chart, if the coin being observed by the user has no update from a trade in the time of that 1 sec candle it is skipped over. This means that a coin with a ton of volume might fill an entire 60 seconds with 60 candles and conversely with a low volume coin there could be as little as 0 1-second candles. BUT even for normally low volume coins, when a pump is beginning with the coin it could literally go from 0 1-second candles within a minute to 60 1-second candles within the next minute. ***NOTE: This DOES NOT show ANY information if the coin is going up or down but rather that a LOT more trading volume is occurring than normal.*** What this script does is scans (via request.security feature) up to 40 coins at a time and counts how many candles are printed within a user set timespan calculated in minute. 1 candle print per incremented timeframe that the chart is on. ie. if the chart is a 1 min chart it counts how many 1 min candles are printed. So, (as is in the captured image for the script) if you wanted to count how many 5 second candles are printed for each coin in 1 min then you would have to put the charts timeframe on 5sec and the setting titled 'Window of TIME(in minutes) to count bars' as 1.0 (which bc it's in minutes 1.0m = 60sec and bc 60s / 5s = 12 there would be 12 possible values that each coin can be at depending on how many bars are counted within that 1min/60sec. *** I will update to show an image of what I'm talking about here. Now, the exchange I'm scanning here is Kucoin's Margin Coins. There are 170 something coins total but I removed a few i didn't care for to make it a round 40 coins per set (there being 4 sets of 40 coins total=160 coins being scanned). To scan all 4 sets the indicator must be added 4 times to the chart and a different 'set' selected for each iteration of the script on the chart. Free users can only scan 3 at the most. All others can scan all 4 sets. In the script you can change the exchange and coins as necessary. If there done so and there are not 40 coins total just put '' '' in the extra coins spots that are not filled and the script will skip over these blankly filled spots. The suffix (traded pair) for the tickerID on all Kucoin's Margin Coin's is USDT so that's what i have inputted in the main function on line 46 (will need to be changed if that differs from the coins you want to scan. Next in the line of settings is 'Window of TIME(in minutes) to count bars' which has already been discussed. Following that is the setting "Table Shows" which the results are all in a table and the table will present the coins that have either "Passed" or "Failed" depending on which you choose. The next setting determines what passes or fails. If there are 12 possible rows for the coins to be in (as described above) then this setting is the "Pass/Fail Cutoff" level. So if you want to show all the coins that are in rows 11 and 12 (as in the image at top) then 11 should be selected here. At this point you will see all the coins that have a lot of volume in them. Finding coin names in the table that are usually not with a ton of volume will present your present movers. NOTE: coins like BTC and ETH will almost always be in these levels so it does not indicate anything different from the norm of these coins. Last setting is the ability to show the table on the main window or not. Hope you enjoy and find use in it. BTW this screener format is the same as the others I have published. If you like, check those out too. If you find difficulty using then refer to those as well as they have additional info in them on how to use the scanner and its format. Lastly, in the script is the ability to print the plots and labels but I commented them out bc its really just a jumbled mess. In the commented out sections there is a Random Color Function (provided by @hewhomustnotbenamed which was developed on the basis of Function-HSL-color by @RicardoSantos. All right, peace brothers....and sisters.
**** Also, I see how the "levels" could be confusing so I will put them into a % format soon (probably not today) so that the "Pass/Fail Cutoff" can be in % format so that if "passed" is chosen and 50% is chosen (in the new setting that will be changed) then it'll show you all the coins that have more than 50% of the bars printed within the time window chosen. Goodluck in all your trading adventures. ChasinAlts out.

MACD ReLoaded STRATEGYSTRATEGY version of MACD ReLOADED Indicator:
A different approach to Gerald Appel's classical Moving Average Convergence Divergence.
Appel originaly set MACD with exponential moving averages.
In this version users can apply 11 different types of moving averages which they can benefit from their smoothness and vice versa sharpnesses...
Built in Moving Average type defaultly set as VAR but users can choose from 11 different Moving Average types like:
SMA : Simple Moving Average
EMA : Exponential Moving Average
WMA : Weighted Moving Average
DEMA : Double Exponential Moving Average
TMA : Triangular Moving Average
VAR : Variable Index Dynamic Moving Average a.k.a. VIDYA
WWMA : Welles Wilder's Moving Average
ZLEMA : Zero Lag Exponential Moving Average
TSF : True Strength Force
HULL : Hull Moving Average
TILL : Tillson T3 Moving Average
In shorter time frames backtest results shows us TILL, WWMA, VIDYA (VAR) could be used to overcome whipsaws because they have less numbers of signals.
In longer time frames like daily charts WMA, Volume Weighted MACD V2, and MACDAS and SMA are more accurate according to backtest results.
My interpretation of Buff Dormeier's Volume Weighted MACD V2:
Thomas Aspray's MACD: (MACDAS)

MACD ReLoadedA different approach to Gerald Appel's classical Moving Average Convergence Divergence.
Appel originaly set MACD with exponential moving averages.
In this version users can apply 11 different types of moving averages which they can benefit from their smoothness and vice versa sharpnesses...
Built in Moving Average type defaultly set as VAR but users can choose from 11 different Moving Average types like:
SMA : Simple Moving Average
EMA : Exponential Moving Average
WMA : Weighted Moving Average
DEMA : Double Exponential Moving Average
TMA : Triangular Moving Average
VAR : Variable Index Dynamic Moving Average a.k.a. VIDYA
WWMA : Welles Wilder's Moving Average
ZLEMA : Zero Lag Exponential Moving Average
TSF : True Strength Force
HULL : Hull Moving Average
TILL : Tillson T3 Moving Average
In shorter time frames backtest results shows us TILL, WWMA, VIDYA (VAR) could be used to overcome whipsaws because they have less numbers of signals.
In longer time frames like daily charts WMA, Volume Weighted MACD V2, and MACDAS and SMA are more accurate according to backtest results.
My interpretation of Buff Dormeier's Volume Weighted MACD V2:
Thomas Aspray's MACD: (MACDAS)

Sortino RatioThe Sortino ratio is a variation of the Sharpe ratio that differentiates harmful volatility from total overall volatility using the asset's standard deviation of negative portfolio returns—downside deviation—instead of the total standard deviation of portfolio returns. The Sortino ratio takes an asset or portfolio's return and subtracts the risk-free rate and then divides that amount by the asset's downside deviation. The ratio was named after Frank A. Sortino.
What Can the Sortino Ratio Tell You?
The Sortino ratio is useful for investors, analysts, and portfolio managers to evaluate an investment's return for a given level of bad risk. Since this ratio uses only the downside deviation as its risk measure, it addresses the problem of using total risk, or standard deviation, which is important because upside volatility is beneficial to investors and isn't a factor most investors worry about.
The Difference Between the Sortino Ratio and the Sharpe Ratio
The Sortino ratio improves upon the Sharpe ratio by isolating downside or negative volatility from total volatility by dividing excess return by the downside deviation instead of the total standard deviation of a portfolio or asset.
The Sharpe ratio punishes the investment for good risk, which provides positive returns for investors. However, determining which ratio to use depends on whether the investor wants to focus on total or standard deviation or just downside deviation.
CONCLUSION: THE HIGHER THE RATIO, THE BETTER IT IS.
Note: The default risk-free rate is based on the Malaysian rate. Please change based on your country rate.
Note: The default length is based on 1 year Malaysia trading day (11/6/2020 - 11/6/2021).
Note: Sortino ratio is good for assessing a long-term investment, and thus, please use a longer time frame to get a better risk assessment.
Please let me know if this script contains any mistake. Cheers!

Stochastic RSI - DurbtradeDurbtrade Stoch RSI -
1) Stoch RSI
A) The K line can be customized to change color based on vertical direction.
B) The space between K line and D line can be filled with a color depending on whether K line is above or below the D line.
C) There are color-coded, cross-over and cross-under background fills, to signal when the K line crosses the D line.
D) K line is drawn in front of D line (D line is drawn behind K line).
E) Default values : K = 3, D = 4, RSI Length = 14, Stoch Length = 14
2) Horizontal Lines
A) Horizontal lines can be drawn automatically, so you don't have to draw them, and they don't extend past the current bar.
B) There are 11 customizable horizontal lines,
and each line is set to non-customizable increments (zero, 10, 20, 30, 40, fifty, 60, 70, 80, 90, hundred).
C) The 11 lines are divided into 2 groups:
a) 4 PAIRS of lines WITH fill options (10/90, 20/80, 30/70, 40/60... 8 lines total), and
b) 3 INDIVIDUAL lines WITHOUT fill options (zero, fifty, hundred).
D) The 4 fills give you the option to fill the space between each pair with a customizable color and opacity,
regardless of whether the lines themselves are drawn or not.
(all default values are what I feel work best for this indicator...
and initially, only the zero, fifty, and hundred lines are drawn automatically .
You may add the other lines if you choose to, by adjusting the opacity to your liking).
3) Conclusion
A) As with my previous indicators, this one maximizes information, color, discernment, clarity, and customization.
B) It is optimized for your ability to be able to easily customize the indicator according to your preferences...
for use on your own personal television, laptop, or cellular phone screen setup... and on all chart zoom levels and layouts.
C) Please feel free to comment your thoughts, critiques, or suggestions. They are all helpful!
D) Check out my previous pine script indicators if you like this one. They work really well together.
E) I hope that you find this script useful.
F) Enjoy!
//Durbtrade

Gann Circle Intraday LevelsThis indicator is an intraday version of Gann Circle Swing Levels indicator. It further divides the Gann Circle into the Eighths in order to generate intraday Levels.
Introduction
This indicator is based on W. D. Gann's Square of 9 Chart and can be interpreted as the Gann Circle / Gann Wheel / 360 Degree Circle Chart or Square of the Circle Chart for intraday usage.
Spiral arrangement of numbers on the Square of 9 chart creates a very unique square root relationship amongst the numbers on the chart. If you take any number on the Square of 9 chart, take the square root of the number, then add 2 to the root and re-square it, resulting in one full 360 degree cycle (i.e. a 360 degree Circle) out from the center of the chart.
For example,
the square root of 121 = 11,
11 + 2 = 13,
and the square of 13 = 169
The number 169 is one full 360 degree cycle out (with reference to 121) from the center of the Square of 9 chart. If we further divide the circle in eight equal parts of 45 degree each, following intermediate resistance levels (ascending) would be generated:
127 (45 degree)
133 (90 degree)
139 (135 degree)
145 (180 degree)
151 (225 degree)
157 (270 degree)
163 (315 degree)
Similarly, if you take any number on the Square of 9 chart, take the square root of the number, then subtract 2 from the root and re-square it, resulting in one full 360 degree inward rotation towards the center of the chart.
For example,
the square root of 565 = 23.77,
23.77 - 2 = 21.77,
and the square of 21.77 = 473.93 (approximately equal to 474, which is directly below 565 on the Square of 9 chart)
The number 474 is one full 360 degree inward rotation (with reference to 565) towards the center of the chart. If we further divide the circle in eight equal parts of 45 degree each, following intermediate support levels (descending) would be generated:
553 (45 degree)
541 (90 degree)
529 (135 degree)
518 (180 degree)
507 (225 degree)
496 (270 degree)
485 (315 degree)
How to Use this Indicator ?
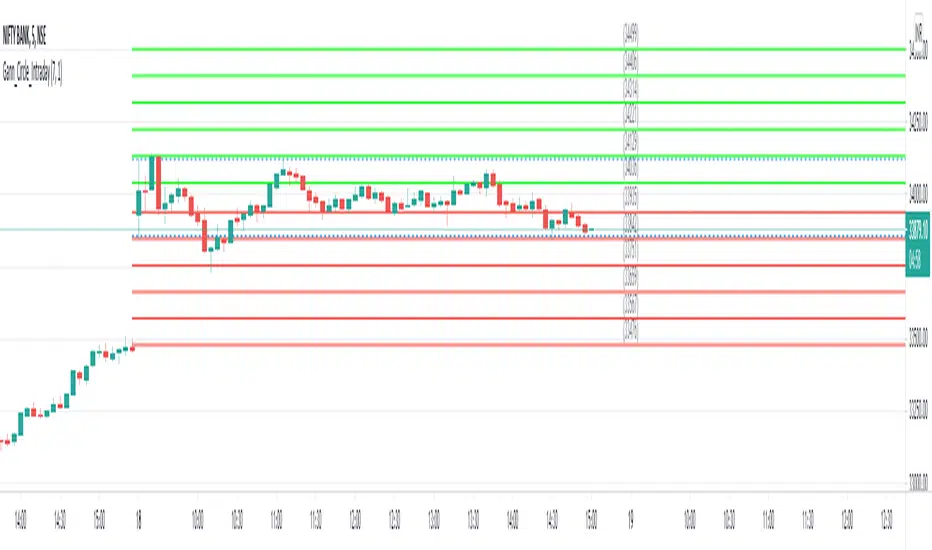
This indicator is designed to generate Gann Circle Intraday Levels based on HIGH and LOW of the opening bar for the day. You may use the bar interval (1 minute, 3 minutes, 5 minutes, 15 minutes etc.) which is suitable for the underlying instrument. Support and resistance lines for the day would be generated only after confirmation of the opening bar of the day.
Input :
Number of Gann Levels (Number of Gann Levels to be projected)
Color codes for the Support and Resistance Levels
Output :
Gann Support or Resistance Levels:
HIGH and LOW of the Opening bar for the day (dashed BLUE lines)
Support levels calculated with reference to the HIGH of the opening bar
Resistance levels calculated with reference to the LOW of the opening bar
Gann Circle Swing LevelsThis indicator is based on W. D. Gann's Square of 9 Chart and can be interpreted as the Gann Circle / Gann Wheel / 360 Degree Circle Chart or Square of the Circle Chart.
Spiral arrangement of numbers on the Square of 9 chart creates a very unique square root relationship amongst the numbers on the chart. If you take any number on the Square of 9 chart, take the square root of the number, then add 2 to the root and re-square it, resulting in one full 360 degree cycle (i.e. a 360 degree Circle) out from the center of the chart.
For example,
the square root of 121 = 11,
11 + 2 = 13,
and the square of 13 = 169
The number 169 is one full 360 degree cycle out (with reference to 121) from the center of the Square of 9 chart.
Similarly, if you take any number on the Square of 9 chart, take the square root of the number, then subtract 2 from the root and re-square it, resulting in one full 360 degree inward rotation towards the center of the chart.
For example,
the square root of 565 = 23.77,
23.77 - 2 = 21.77,
and the square of 21.77 = 473.93 (approximately equal to 474, which is directly below 565 on the Square of 9 chart)
The number 474 is one full 360 degree inward rotation (with reference to 565) towards the center of the chart.
How to Use this Indicator ?
This indicator is useful for finding coordinate squares on the Gann Circle that are making hard aspects to a previous position (such as a significant top or bottom) on the circle.
Input :
Swing Point (Significant price point, such as a top or a bottom)
Low / High ? (Is it a bottom or a top)
Number of Gann Levels (Number of Gann Cycles to be projected)
Output :
Gann Support or Resistance Levels (color coded as follows) :
Swing High or Swing Low (BLUE)
Support levels calculated with reference to the Swing High (RED)
Resistance levels calculated with reference to the Swing Low (LIME)
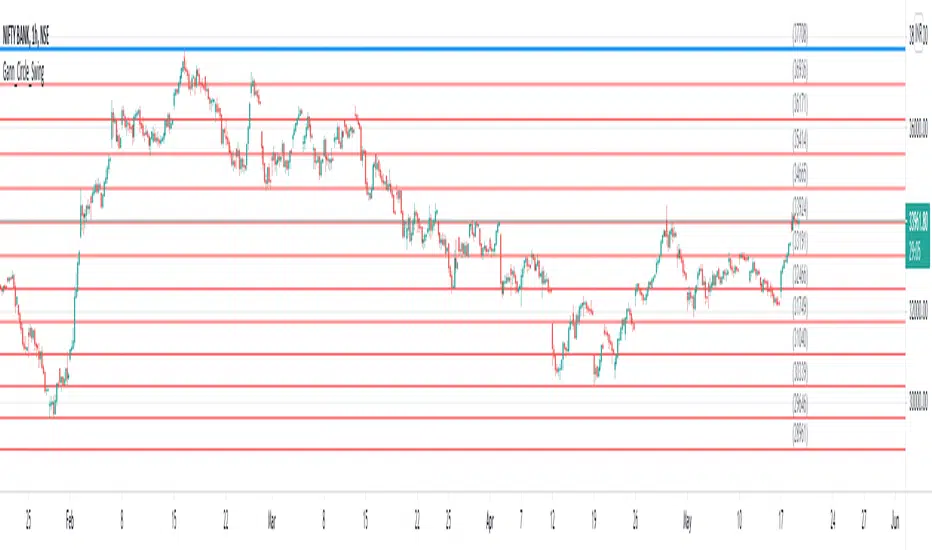
RSI Relative Strength Index 3X - DurbtradeDurbtrade Triple RSI - 3 individual RSI's on 1 indicator, each distinguishable by length, as well as line color, thickness, opacity, and type.
(note: usable line TYPES are limited... try experimenting)
1) RSI's
A) Each RSI can be customized to change color based on RSI vertical direction (default = only RSI #1 changes color).
B) All 3 RSI's use a single Source (default Close).
C) You may customize the length of each RSI individually (I LOVE my default 14, 7, and 3!).
D) RSI #1 is the primary RSI, and is plotted LAST, so that it is drawn ABOVE RSI #2, which is drawn above RSI #3.
2) Horizontal Lines
A) Horizontal lines are also drawn automatically, so you don't have to, and they don't extend past the current bar.
B) There are 11 customizable lines, and each one is set to non-customizable increments (zero, 10, 20, 30, 40, fifty, 60, 70, 80, 90, hundred).
C) The 11 lines are divided into 2 groups:
a) 4 PAIRS of lines WITH fill options (10/90, 20/80, 30/70, 40/60... 8 lines total), and
b) 3 INDIVIDUAL lines WITHOUT fill options (zero, fifty, hundred).
D) The 4 fills give you the option to fill the space between each pair with a customizable color and opacity (the default is what I personally feel is best for each).
3) Conclusion
A) As with my previous indicators, this one maximizes information, discernment, clarity, and customization.
B) It is optimized for your ability to be able to customize a relatively basic but important indicator with ease
for use on your own personal television, laptop, or cellular phone screen setup... and on all chart zoom levels and layouts.
B) And, this being my 3rd script, please feel free to comment, critique, or leave suggestions. I find them helpful!
C) Check out my previous pine scripts if you like this one. They work well together.
D) I hope that you find this useful.
E) Enjoy!
//Durbtrade

SectorsThis script attempts to show the relative strength of the 11 sectors in the SPX, which can be accomplished in three ways:
1. Sectors - displays all sector indices as they appear normally
2. Sector Relativity - displays each sector divided by the sum of the other 10 sectors
3. Sector Alpha - displays the alpha of each sector as compared to the sum of the other 10 sectors
I have seen some other iterations of this script that compare each sector to the SPX as a whole, a couple problems with that:
1. SPX sector weightings are unequal and change quarterly, meaning you will get an inaccurate depiction of relative sector strength across time.
2. Even if using an equal-weight SPX, you would be comparing a sector to itself as all 11 sectors are included in the SPX, not just the complementary 10 you are looking to compare one sector to.
For more information on the sectors in the SPX or the calculation of Alpha, visit the links at the top of the script.
*Includes an option for repainting -- default value is true, meaning the script will repaint the current bar.
False = Not Repainting = Value for the current bar is not repainted, but all past values are offset by 1 bar.
True = Repainting = Value for the current bar is repainted, but all past values are correct and not offset by 1 bar.
In both cases, all of the historical values are correct, it is just a matter of whether you prefer the current bar to be realistically painted and the historical bars offset by 1, or the current bar to be repainted and the historical data to match their respective price bars.
As explained by TradingView,`f_security()` is for coders who want to offer their users a repainting/no-repainting version of the HTF data.

Power Bar [racer8]Introduction: 🌟
The Power Bar indicator is a powerful volatility indicator that can detect power bars 💪. A power bar is just a really big price bar that forms after a price base. A price base is chart pattern consisting of many low volatility price bars (bars that have small ranges). To detect such powerful bars, the PB indicator uses the following formula:
PB = ( Absolute value of current close - previous close ) / ( Previous price range over n periods )
Looking at the formula, you can see that PB compares the current change in closing price to the n-period base pattern's range. Strong PB values are typically greater than a value of 1. If n periods = 10, the indicator will look back 11 periods. The 11 periods includes the 10-period base plus the current price bar. 10 periods is the default setting for the indicator.
After the calculation, PB is then plotted as a histogram. Along with the histogram, a horizontal dashed line is also plotted.
PB's other setting controls the dashed line's level. This level is preset at a default value of 1. The dashed line is just a way to filter out weak PB values, and to generate signals. A signal is generated when the PB histogram is above the dashed line.
Objective: 🤔
This indicator shall prove very useful to you if your main objective is to trade only the best chart pattern in the market...and the base pattern is one of the best, if not the best chart pattern that exists today. This indicator is a mechanical way of detecting the chart pattern.
Enjoy! 🥳

MA+ADX+DMICOINBASE:BTCUSD
BINANCE:BTCUSDT
Use long and short moving average to look for a potential price in/out. (default as 14 and 7, bases on the history experience)
ADX and DMI to prevent the small volatility and tangling MA.
Test it in 4HR, "BINANCE:BTCUSDT"
From 12/1/2017- 11/1/2020 (Mixed Bull/Bear market)
Overall Profit: 560.89%
From 1/1/2018 - 1/1/2019 (Bear market)
Overall Profit: -2.19%
From 4/1/2020 - 11/1/2020 (Bull Market)
Overall Profit: 274.74%
Any suggestion is welcome to discuss.
Bullish and Bearish by NicolErazoFThis indicator changes the color of the candlesticks when there’s a change in the trend to the rising or falling trend.
BEARISH ENGULFING: Yellow candlestick. It is an engulfing falling trend reversal; you must make a sell decision.
BEARISH HARAMI: White candlestick. Indicates a possible falling trend change, you must be alert for a possible sale.
BULLISH ENGULFING: Black candlestick. It is a change in the engulfing rising trend, you must make a purchase decision.
BULLISH HARAMI: Blue candlestick. Indicates a possible rising trend change, you should be alert for a possible purchase.
On the chart, you can see the 4 candles, on September 11 the black candle appears indicating a change in the uptrend. But today, the white candle is seen, which appears on September 8, indicating a rebound with a possible change in trend to bearish.
Previous days, on August 26, you see the blue candle with a possible change in the upward trend, which then, on August 28, a yellow candle appears with a change in the downward trend.
The Engulfing indicator (yellow and black) says that the candle has an engulfing change that is radical.
On the other hand, the Harami (blue and white) indicates a possible change in trend that must be previously analyzed.
Harami candles are smaller than Engulfing candles, since Harami in a Japanese term that means pregnancy, where the previous candle is the woman and the next candle is the baby.
___________________________________________________________________________
ESPAÑOL
Este indicador cambia las velas de color cuando ocurre un cambio de tendencia ALCISTA o BAJISTA
BEARISH ENGULFING: Vela de color amarillo. Es una cambio de tendencia bajista envolvente, debes tomar una decisión de venta.
BEARISH HARAMI: Vela de color blanco. Indica un posible cambio de tendencia bajista, debes estar alerta para una posible venta.
BULLISH ENGULFING: Vela de color negro. Es un cambio de tendencia alcista envolvente, debes tomar una decisión de compra.
BULLISH HARAMI: Vela de color azul. Indica un posible cambio de tendencia alcista, debes estar alerta para una posible compra.
En el gráfico, se pueden ver las 4 velas, el 11 de Septiembre aparece la vela negra que indica un cambio de tendencia alcista. Pero hoy, se ve la vela blanca, que aparece el 8 de septiembre, indicando un rebote con un posible cambio de tendencia a bajista.
Días anteriores, el 26 de Agosto, se ve la vela azul con un posible cambio de tendencia alcista, que luego, el 28 de agosto aparece una vela amarilla con cambio de tendencia bajista.
El indicador Engulfing (amarillo y negro) dice que la vela tiene un cambio envolvente que es radical.
En cambio, el Harami (azul y blanco) indica un posible cambio de tendencia que debe ser previamente analizado.
Las velas Harami son más pequeñas que las Engulfing , ya que Harami en un término japonés que significa embarazo, en donde la vela anterior es la mujer y la vela siguiente es el bebé.
KingEMA21-55ZoneI used the moving average with the habit of 21-55, so added two moving average
When the price runs above 55, it only looks for the buy signal.
When the price runs below 55, it only looks for sell signals.
The first step up through the 55 moving average after the first confirmation can buy homeoply,
The first pull down after crossing the 55 moving average for the first time confirms that it can be sold in line with the trend.
Price horizontal finishing, moving average frequently across the field observation.
The yellow area in the interval from 81to 55 is the homeopathic warehouse addition signal.
When the price is above the 55 moving average, the k-line closes below the 21-day moving average as a callback signal
Prices below the 55 ema close above the 21 - day ema as a rebound signal
After the correction and rebound signals come out, we should make half of the profit and the other half of the stop loss in the break-even place.
Moving average is very suitable for the trend of strong varieties, is not suitable for volatile market.
Only at the end of the shock market moving average upward or downward divergent when it is possible to be used.
1. Repeatedly entangle the mean line of horizontal disk stage and observe it from the field
2. Sell the three EMA moving averages when they can't exceed 89EMA with downward crossing
3, many times can not break the new low when prices go sideways profit
4. Buy when the price reaches 89EMA after the convergence of triangle 3 is broken
5, the Angle of price rise slowed and closed below the 21 moving average when profit
6. Left field observation during transverse oscillation.
Sit tight while news or data cause prices to fall quickly
8. Buy when the price triangle breaks through the 55 moving average upward
9, the price does not rise to slow down when the horizontal closed below the 21 moving average when profit
10, price horizontal shock finishing at the same time the average line also transverse finishing field observation
11, the price of the triangle after finishing through the 89 moving average to buy.At this point all the averages have turned up
12, the second time can not break through the new high when the negative line can profit
13, the price of the first time in the same period of time through 89 after the first step back can be re-bought.
中文翻译
价格在55上面运行时时只找买入信号、
价格在55下面运行时只寻找卖出信号、
第一次向上穿过55均线后的第一次回踩确认可以顺势买入、
第一次向下穿过55均线后的第一次回抽确认可以顺势卖出、
价格横盘整理,均线频繁穿越时离场观察。
21-55区间里面黄色区域为顺势加仓信号,
价格在55均线上面时K线收盘在21天均线下面时为回调信号
价格在55均线下面时K线收盘在21天均线上面时为反弹信号
在回调和反弹信号出来之后我们应该获利一半的头寸,另外一半止损放到盈亏平衡的地方。
均线非常适合趋势性很强的品种,并不适合震荡行情。
只有在震荡行情结束时均线向上或向下发散时才有被运用的可能。
1、横盘阶段均线反复纠缠,离场观察
2、三条EMA均线向下交叉回抽无法超越55EMA时卖出
3、多次不能破新低时价格走横时获利
4、价格在3处三角形收敛被突破后站上了55EMA时买入
5、价格上涨角度变缓并收盘在21均线下面时获利
6、横盘震荡时离场观察。
7、见死不救新闻或数据导致价格快速下跌时观望
8、价格三角形向上突破时穿过55均线时买入
9、价格不升减速走横时收盘于21均线下面时获利
10、价格横盘震荡整理同时均线也横向整理时离场观察
11、价格突破三角形整理后重新穿过89均线时买入。此时所有均线已经向上翘头
12、第二次不能突破新高时收阴线可以获利
13、价格在同一个时间周期内第一次穿过89以后的第一次回踩可以重新买入
14、21-55作为牛熊的分水岭。在21-55区域之下只考虑做空,21-55之上只考虑做多。如果21-55走横则以位置决定高位倾向空低位倾向多。
15、K线会因为指标的设置自动变成两个颜色块,绿色看涨,红色看跌。做趋势看K线颜色。牛市的红色可以当成入场K熊市绿色当成入场K

KingEMA21-55-89-144I used the moving average with the habit of 21-55, so added two moving average, one is the short line 8EMA, the other is the medium and long line 89ema
Explain the application of moving averages through the disk surface:
When the price runs above 89, it only looks for the buy signal.
When the price runs below 89, it only looks for sell signals.
The first step up through the 89 moving average after the first confirmation can buy homeoply,
The first pull down after crossing the 89 moving average for the first time confirms that it can be sold in line with the trend.
Price horizontal finishing, moving average frequently across the field observation.
The yellow area in the interval from 8 to 21 is the homeopathic warehouse addition signal.
When the price is above the 89 moving average, the k-line closes below the 21-day moving average as a callback signal
Prices below the 89 ema close above the 21 - day ema as a rebound signal
After the correction and rebound signals come out, we should make half of the profit and the other half of the stop loss in the break-even place.
Moving average is very suitable for the trend of strong varieties, is not suitable for volatile market.
Only at the end of the shock market moving average upward or downward divergent when it is possible to be used.
1. Repeatedly entangle the mean line of horizontal disk stage and observe it from the field
2. Sell the three EMA moving averages when they can't exceed 89EMA with downward crossing
3, many times can not break the new low when prices go sideways profit
4. Buy when the price reaches 89EMA after the convergence of triangle 3 is broken
5, the Angle of price rise slowed and closed below the 21 moving average when profit
6. Left field observation during transverse oscillation.
Sit tight while news or data cause prices to fall quickly
8. Buy when the price triangle breaks through the 89 moving average upward
9, the price does not rise to slow down when the horizontal closed below the 21 moving average when profit
10, price horizontal shock finishing at the same time the average line also transverse finishing field observation
11, the price of the triangle after finishing through the 89 moving average to buy.At this point all the averages have turned up
12, the second time can not break through the new high when the negative line can profit
13, the price of the first time in the same period of time through 89 after the first step back can be re-bought.
中文翻译
价格在89上面运行时时只找买入信号、
价格在89下面运行时只寻找卖出信号、
第一次向上穿过89均线后的第一次回踩确认可以顺势买入、
第一次向下穿过89均线后的第一次回抽确认可以顺势卖出、
价格横盘整理,均线频繁穿越时离场观察。
8-21区间里面黄色区域为顺势加仓信号,
价格在89均线上面时K线收盘在21天均线下面时为回调信号
价格在89均线下面时K线收盘在21天均线上面时为反弹信号
在回调和反弹信号出来之后我们应该获利一半的头寸,另外一半止损放到盈亏平衡的地方。
均线非常适合趋势性很强的品种,并不适合震荡行情。
只有在震荡行情结束时均线向上或向下发散时才有被运用的可能。
1、横盘阶段均线反复纠缠,离场观察
2、三条EMA均线向下交叉回抽无法超越89EMA时卖出
3、多次不能破新低时价格走横时获利
4、价格在3处三角形收敛被突破后站上了89EMA时买入
5、价格上涨角度变缓并收盘在21均线下面时获利
6、横盘震荡时离场观察。
7、见死不救新闻或数据导致价格快速下跌时观望
8、价格三角形向上突破时穿过89均线时买入
9、价格不升减速走横时收盘于21均线下面时获利
10、价格横盘震荡整理同时均线也横向整理时离场观察
11、价格突破三角形整理后重新穿过89均线时买入。此时所有均线已经向上翘头
12、第二次不能突破新高时收阴线可以获利
13、价格在同一个时间周期内第一次穿过89以后的第一次回踩可以重新买入
14、21-55作为牛熊的分水岭。在21-55区域之下只考虑做空,21-55之上只考虑做多。如果21-55走横则以位置决定高位倾向空低位倾向多。
15、K线会因为指标的设置自动变成两个颜色块,绿色看涨,红色看跌。做趋势看K线颜色。牛市的红色可以当成入场K熊市绿色当成入场K
