PIVOT STRATEGY [INDIAN MARKET TIMING]
A Back-tested Profitable Strategy for Free!!
A PIVOT INTRADAY STRATEGY for 5 minute Time-Frame , that also explains the time condition for Indian Markets
The Timing can be changed to fit other markets, scroll down to "TIME CONDITION" to know more.
The commission is also included in the strategy .
The basic idea is when ,
1) Price crosses above ema1 ,indicated by pivot highest line in green color .
2) Price crosses below ema1 ,indicated by pivot lowest line in red color .
3) Candle high crosses above pivot highest , is the Long condition .
4) Candle low crosses below pivot lowest , is the Short condition .
5) Maximum Risk per trade for the intraday trade can be changed .
6) Default_qty_size is set to 60 contracts , which can be changed under settings → properties → order size .
7) ATR is used for trailing after entry, as mentioned in the inputs below.
// ═════════════════════════//
// ————————> INPUTS <————————— //
// ═════════════════════════//
Leftbars —————> Length of pivot highs and lows
Rightbars —————> Length of pivot highs and lows
Price Cross Ema —————> Added condition
ATR LONG —————> ATR stoploss trail for Long positions
ATR SHORT —————> ATR stoploss trail for Short positions
RISK —————> Maximum Risk per trade for the day
The strategy was back-tested on RELIANCE ,the input values and the results are mentioned under "BACKTEST RESULTS" below .
// ═════════════════════════ //
// ————————> PROPERTIES<——————— //
// ═════════════════════════ //
Default_qty_size ————> 60 contracts , which can be changed under settings
↓
properties
↓
order size
// ═══════════════════════════════//
// ————————> TIME CONDITION <————————— //
// ═══════════════════════════════//
The time can be changed in the script , Add it → click on ' { } ' → Pine editor→ making it a copy [right top corner} → Edit the line 25 .
The Indian Markets open at 9:15am and closes at 3:30pm .
The 'time_cond' specifies the time at which Entries should happen .
"Close All" function closes all the trades at 3pm, at the open of the next candle.
To change the time to close all trades , Go to Pine Editor → Edit the line 103 .
All open trades get closed at 3pm , because some brokers don't allow you to place fresh intraday orders after 3pm .
NSE:RELIANCE
// ═══════════════════════════════════════════════ //
// ————————> BACKTEST RESULTS ( 128 CLOSED TRADES )<————————— //
// ═══════════════════════════════════════════════ //
INPUTS can be changed for better back-test results.
The strategy applied to NIFTY ( 5 min Time-Frame and contract size 60 ) gives us 60% profitability y , as shown below
It was tested for a period a 6 months with a Profit Factor of 1.45 ,net Profit of 21,500Rs profit .
Sharpe Ratio : 0.311
Sortino Ratio : 0.727
The graph has a Linear Curve with consistent profits .
The INPUTS are as follows,
1) Leftbars ————————> 3
2) Rightbars ————————> 5
3) Price Cross Ema ——————> 150
4) ATR LONG ————————> 2.7
5) ATR SHORT ———————> 2.9
6) RISK —————————> 2500
7) Default qty size ——————> 60
NSE:RELIANCE
Save it to favorites.
Apply it to your charts Now !!
↓
FOLLOW US FOR MORE !
Thank me later ;)
Search in scripts for "technical"

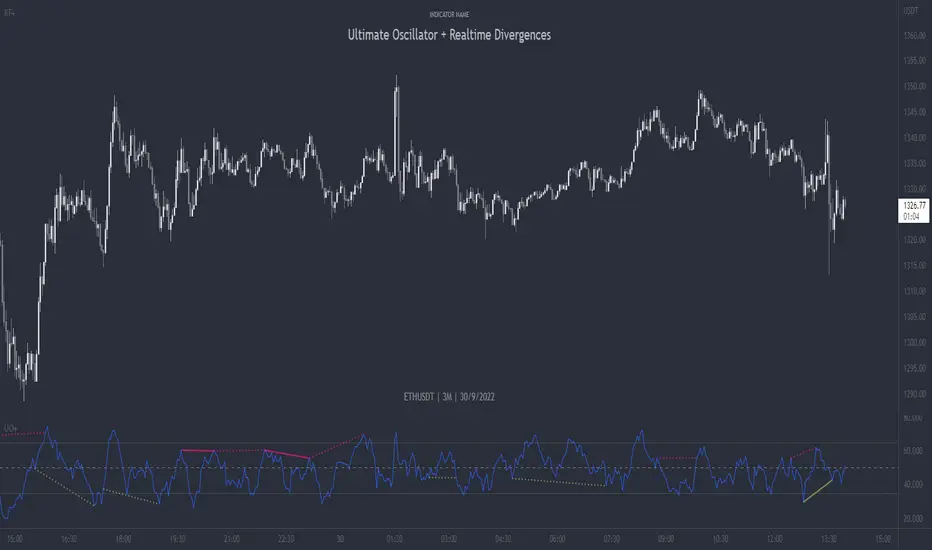
Ultimate Oscillator + Realtime DivergencesUltimate Oscillator (UO) + Realtime Divergences + Alerts + Lookback periods.
This version of the Ultimate Oscillator adds the following 5 additional features to the stock UO by Tradingview:
- Optional divergence lines drawn directly onto the oscillator in realtime
- Configurable alerts to notify you when divergences occur, as well as centerline crossovers.
- Configurable lookback periods to fine tune the divergences drawn in order to suit different trading styles and timeframes.
- Background colouring option to indicate when the UO has crossed the centerline, or optionally when both the UO and an external oscillator, which can be linked via the settings, have both crossed their centerlines.
- Alternate timeframe feature allows you to configure the oscillator to use data from a different timeframe than the chart it is loaded on.
This indicator adds additional features onto the stock Ultimate Oscillator by Tradingview, whose core calculations remain unchanged. Namely the configurable option to automatically and clearly draw divergence lines onto the oscillator for you as they occur in realtime. It also has the addition of unique alerts, so you can be notified as divergences occur without spending all day watching the charts. Furthermore, this version of the Ultimate Oscillator comes with configurable lookback periods, which can be configured in order to adjust the length of the divergences, in order to suit shorter or higher timeframe trading approaches.
The Ultimate Oscillator
Tradingview describes the Ultimate Oscillator as follows:
“The Ultimate Oscillator indicator (UO) indicator is a technical analysis tool used to measure momentum across three varying timeframes. The problem with many momentum oscillators is that after a rapid advance or decline in price, they can form false divergence trading signals. For example, after a rapid rise in price, a bearish divergence signal may present itself, however price continues to rise. The ultimate Oscillator attempts to correct this by using multiple timeframes in its calculation as opposed to just one timeframe which is what is used in most other momentum oscillators.”
More information on the history, use cases and calculations of the Ultimate Oscillator can be found here: www.tradingview.com
What are divergences?
Divergence is when the price of an asset is moving in the opposite direction of a technical indicator, such as an oscillator, or is moving contrary to other data. Divergence warns that the current price trend may be weakening, and in some cases may lead to the price changing direction.
There are 4 main types of divergence, which are split into 2 categories;
regular divergences and hidden divergences. Regular divergences indicate possible trend reversals, and hidden divergences indicate possible trend continuation.
Regular bullish divergence: An indication of a potential trend reversal, from the current downtrend, to an uptrend.
Regular bearish divergence: An indication of a potential trend reversal, from the current uptrend, to a downtrend.
Hidden bullish divergence: An indication of a potential uptrend continuation.
Hidden bearish divergence: An indication of a potential downtrend continuation.
Setting alerts.
With this indicator you can set alerts to notify you when any/all of the above types of divergences occur, on any chart timeframe you choose.
Configurable lookback values.
You can adjust the default lookback values to suit your prefered trading style and timeframe. If you like to trade a shorter time frame, lowering the default lookback values will make the divergences drawn more sensitive to short term price action.
How do traders use divergences in their trading?
A divergence is considered a leading indicator in technical analysis , meaning it has the ability to indicate a potential price move in the short term future.
Hidden bullish and hidden bearish divergences, which indicate a potential continuation of the current trend are sometimes considered a good place for traders to begin, since trend continuation occurs more frequently than reversals, or trend changes.
When trading regular bullish divergences and regular bearish divergences, which are indications of a trend reversal, the probability of it doing so may increase when these occur at a strong support or resistance level . A common mistake new traders make is to get into a regular divergence trade too early, assuming it will immediately reverse, but these can continue to form for some time before the trend eventually changes, by using forms of support or resistance as an added confluence, such as when price reaches a moving average, the success rate when trading these patterns may increase.
Typically, traders will manually draw lines across the swing highs and swing lows of both the price chart and the oscillator to see whether they appear to present a divergence, this indicator will draw them for you, quickly and clearly, and can notify you when they occur.
Disclaimer: This script includes code from the stock UO by Tradingview as well as the Divergence for Many Indicators v4 by LonesomeTheBlue.
Variety N-Tuple Moving Averages w/ Variety Stepping [Loxx]Variety N-Tuple Moving Averages w/ Variety Stepping is a moving average indicator that allows you to create 1- 30 tuple moving average types; i.e., Double-MA, Triple-MA, Quadruple-MA, Quintuple-MA, ... N-tuple-MA. This version contains 2 different moving average types. For example, using "50" as the depth will give you Quinquagintuple Moving Average. If you'd like to find the name of the moving average type you create with the depth input with this indicator, you can find a list of tuples here: Tuples extrapolated
Due to the coding required to adapt a moving average to fit into this indicator, additional moving average types will be added as they are created to fit into this unique use case. Since this is a work in process, there will be many future updates of this indicator. For now, you can choose from either EMA or RMA.
This indicator is also considered one of the top 10 forex indicators. See details here: forex-station.com
Additionally, this indicator is a computationally faster, more streamlined version of the following indicators with the addition of 6 stepping functions and 6 different bands/channels types.
STD-Stepped, Variety N-Tuple Moving Averages
STD-Stepped, Variety N-Tuple Moving Averages is the standard deviation stepped/filtered indicator of the following indicator
Last but not least, a big shoutout to @lejmer for his help in formulating a looping solution for this streamlined version. this indicator is speedy even at 50 orders deep. You can find his scripts here: www.tradingview.com
How this works
Step 1: Run factorial calculation on the depth value,
Step 2: Calculate weights of nested moving averages
factorial(depth) / (factorial(depth - k) * factorial(k); where depth is the depth and k is the weight position
Examples of coefficient outputs:
6 Depth: 6 15 20 15 6
7 Depth: 7 21 35 35 21 7
8 Depth: 8 28 56 70 56 28 8
9 Depth: 9 36 34 84 126 126 84 36 9
10 Depth: 10 45 120 210 252 210 120 45 10
11 Depth: 11 55 165 330 462 462 330 165 55 11
12 Depth: 12 66 220 495 792 924 792 495 220 66 12
13 Depth: 13 78 286 715 1287 1716 1716 1287 715 286 78 13
Step 3: Apply coefficient to each moving average
For QEMA, which is 5 depth EMA , the calculation is as follows
ema1 = ta. ema ( src , length)
ema2 = ta. ema (ema1, length)
ema3 = ta. ema (ema2, length)
ema4 = ta. ema (ema3, length)
ema5 = ta. ema (ema4, length)
In this new streamlined version, these MA calculations are packed into an array inside loop so Pine doesn't have to keep all possible series information in memory. This is handled with the following code:
temp = array.get(workarr, k + 1) + alpha * (array.get(workarr, k) - array.get(workarr, k + 1))
array.set(workarr, k + 1, temp)
After we pack the array, we apply the coefficients to derive the NTMA:
qema = 5 * ema1 - 10 * ema2 + 10 * ema3 - 5 * ema4 + ema5
Stepping calculations
First off, you can filter by both price and/or MA output. Both price and MA output can be filtered/stepped in their own way. You'll see two selectors in the input settings. Default is ATR ATR. Here's how stepping works in simple terms: if the price/MA output doesn't move by X deviations, then revert to the price/MA output one bar back.
ATR
The average true range (ATR) is a technical analysis indicator, introduced by market technician J. Welles Wilder Jr. in his book New Concepts in Technical Trading Systems, that measures market volatility by decomposing the entire range of an asset price for that period.
Standard Deviation
Standard deviation is a statistic that measures the dispersion of a dataset relative to its mean and is calculated as the square root of the variance. The standard deviation is calculated as the square root of variance by determining each data point's deviation relative to the mean. If the data points are further from the mean, there is a higher deviation within the data set; thus, the more spread out the data, the higher the standard deviation.
Adaptive Deviation
By definition, the Standard Deviation (STD, also represented by the Greek letter sigma σ or the Latin letter s) is a measure that is used to quantify the amount of variation or dispersion of a set of data values. In technical analysis we usually use it to measure the level of current volatility .
Standard Deviation is based on Simple Moving Average calculation for mean value. This version of standard deviation uses the properties of EMA to calculate what can be called a new type of deviation, and since it is based on EMA , we can call it EMA deviation. And added to that, Perry Kaufman's efficiency ratio is used to make it adaptive (since all EMA type calculations are nearly perfect for adapting).
The difference when compared to standard is significant--not just because of EMA usage, but the efficiency ratio makes it a "bit more logical" in very volatile market conditions.
See how this compares to Standard Devaition here:
Adaptive Deviation
Median Absolute Deviation
The median absolute deviation is a measure of statistical dispersion. Moreover, the MAD is a robust statistic, being more resilient to outliers in a data set than the standard deviation. In the standard deviation, the distances from the mean are squared, so large deviations are weighted more heavily, and thus outliers can heavily influence it. In the MAD, the deviations of a small number of outliers are irrelevant.
Because the MAD is a more robust estimator of scale than the sample variance or standard deviation, it works better with distributions without a mean or variance, such as the Cauchy distribution.
For this indicator, I used a manual recreation of the quantile function in Pine Script. This is so users have a full inside view into how this is calculated.
Efficiency-Ratio Adaptive ATR
Average True Range (ATR) is widely used indicator in many occasions for technical analysis . It is calculated as the RMA of true range. This version adds a "twist": it uses Perry Kaufman's Efficiency Ratio to calculate adaptive true range
See how this compares to ATR here:
ER-Adaptive ATR
Mean Absolute Deviation
The mean absolute deviation (MAD) is a measure of variability that indicates the average distance between observations and their mean. MAD uses the original units of the data, which simplifies interpretation. Larger values signify that the data points spread out further from the average. Conversely, lower values correspond to data points bunching closer to it. The mean absolute deviation is also known as the mean deviation and average absolute deviation.
This definition of the mean absolute deviation sounds similar to the standard deviation (SD). While both measure variability, they have different calculations. In recent years, some proponents of MAD have suggested that it replace the SD as the primary measure because it is a simpler concept that better fits real life.
For Pine Coders, this is equivalent of using ta.dev()
Bands/Channels
See the information above for how bands/channels are calculated. After the one of the above deviations is calculated, the channels are calculated as output +/- deviation * multiplier
Signals
Green is uptrend, red is downtrend, yellow "L" signal is Long, fuchsia "S" signal is short.
Included:
Alerts
Loxx's Expanded Source Types
Bar coloring
Signals
6 bands/channels types
6 stepping types
Related indicators
3-Pole Super Smoother w/ EMA-Deviation-Corrected Stepping
STD-Stepped Fast Cosine Transform Moving Average
ATR-Stepped PDF MA

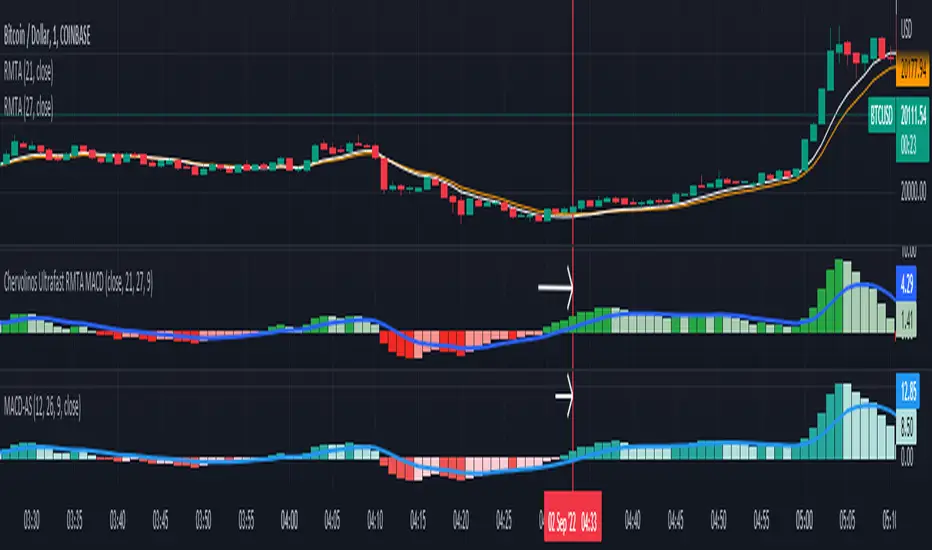
Chervolinos Ultrafast RMTA MACDDescription of a classic MACD:
MACD, short for moving average convergence/divergence, is a trading indicator used in technical analysis of stock prices, created by Gerald Appel in the late 1970s. It is designed to reveal changes in the strength, direction, momentum, and duration of a trend in a stock's price. The MACD indicator (or "oscillator") is a collection of three time series calculated from historical price data, most often the closing price. These three series are: the MACD series proper, the "signal" or "average" series, and the "divergence" series which is the difference between the two. The MACD series is the difference between a "fast" (short period) exponential moving average (EMA), and a "slow" (longer period) EMA of the price series. The average series is an EMA of the MACD series itself. The MACD indicator thus depends on three time parameters, namely the time constants of the three EMAs. The notation "MACD" usually denotes the indicator where the MACD series is the difference of EMAs with characteristic times a and b, and the average series is an EMA of the MACD series with characteristic time c. These parameters are usually measured in days. The most commonly used values are 12, 26, and 9 days, that is, MACD. As true with most of the technical indicators, MACD also finds its period settings from the old days when technical analysis used to be mainly based on the daily charts. The reason was the lack of the modern trading platforms which show the changing prices every moment. As the working week used to be 6-days, the period settings of represent 2 weeks, 1 month and one and a half week. Now when the trading weeks have only 5 days, possibilities of changing the period settings cannot be overruled. However, it is always better to stick to the period settings which are used by the majority of traders as the buying and selling decisions based on the standard settings further push the prices in that direction.
Description of the new Ultrafast RMTA MACD:
Ultrafast RMTA MACD, short for moving average convergence/divergence, is a trading indicator used in technical analysis of stock prices, created by Chervolino. It is designed to reveal changes in the strength,
direction, momentum, and duration of a trend in a stock's price. The RMTA MACD indicator (or "oscillator") is a collection of three time series calculated from historical price data, from the closing price.
The RMTA MACD based on the THE RECURSIVE MOVING TRENDLINE SYSTEM technical.traders.com
and is series is the difference between a "fast" (short period) Recursive Moving Trend Average, and a "slow" (longer period) Recursive Moving Trend Average of the price series. The average series is an EMA of the MACD series itself.
The result is a non laging indicator, depends on the settings.
special thanks to
everget
LonesomeTheBlue
Demand IndexLibrary "DemandIndex"
di()
The Demand Index is a complex technical indicator that uses price and volume to assess buying and selling pressure affecting a security.
James Sibbet established six rules for using Demand Index when the technical indicator was originally published. While traders may use variations of these rules, they serve as a great baseline for using the indicator in practice.
The six rules are as follows:
A divergence between the Demand Index and price is a bearish indication.
Prices often rally to new highs following an extreme peak in the Demand Index.
Higher prices with a low Demand Index often indicate a top in the market.
The Demand Index moving through the zero line suggests a change in trend.
The Demand Index remaining near the zero line indicates weak price movement that won’t last long.
A long-term divergence between the Demand Index and price predicts a major top or bottom.
Traders should use the Demand Index in conjunction with other technical indicators and chart patterns to maximize their odds of success.

Price Action in action
What?
Price Action in Action is an indicator to help Price Action learners and practitioners to get everything related for Price Action in one place.
Price Action is:
Price + Volume = Action
In this indicator, we have the following features available:
Support/Resistance
Using the RSI with different periods in a multiple of 7 (7, 14, 21, 28), we first determine the overbought (above 70, customizable) and oversold (below 30, customizable) regions. Then we pick up the highest point and lowest point in the RSI values in the overbought and oversold regions, respectively. These are the point, historically supply/demand emerged for surety to push down/up the RSI indicator and the corresponding price. So, these are the most accurate way, we believe, to draw support/resistance (or demand/supply) in the chart. By default, the Support is green color and Resistance is red color. To give a visual representation, we differentiate the different shades of green and red. For example, for Level-1 (i.e. 7 by default) we use the darkest shade (0 transparency) and Level-4 (i.e. 28 by default) we use lighter shade (60 transparency). Note please: you can customize the color of support and resistance lines (say if you want resistance as green and support as red). The respective shades (transparency) will be automatically adjusted accordingly. But those shade (transparency) levels are not customizable, they are fixed (please bear with it for version-1 at least).
Strength of Support/Resistance
In the chart above/below the Resistance / Support lines you can see the tiny labels with some numbers like 1, 2.
We found out how many times a particular support/resistance is appearing across multiple RSI periods. E.g. if price P1 appears 2 times among 4 different RSI periods, the number will be 2 for that calculation, and so on.
There can be multiple presence of these numbers in a support/resistance line (i.e. multiple tiny labels). Something like: 1, 1, 2 (into different candles). This means the same support/resistance is tested so many times in different occasion (means there is a RSI max/min coincides in this level over multiple occasions) at different candles.
This will help you to intuitionally gauge the “strength” of a support/resistance line.
The more the marrier, unworthy to mention.
Candle Stick Patterns
Well: we don’t need to tell anything about the Candlestick. All of you know it better than us. And it’s a time proven, zero-lag mechanism to judge the Price-Action is unfolding in the market. We do not know if there is anything better possible than this time tested patterns to judge the prevailing sentiments of market.
Price-Action does not complete without finding out the Candlestick Patterns correctly.
And in this indicator your will get all of these: Single Candle such as Doji (default off), Marubozu, Spinner, hammers, inverted-hammer etc. ; 2 candles like Tweezer, Inside Candle, Engulfing; 3 candles like morning star/evening star.
In the multi candle patterns (2/3 candles), we are grouping the candles with a dotted rectangle such that it is clear which 2/3 candles are part of the pattern. E.g. Morning Star: 3 candles are grouped in a dotted rectangle and the Morning Star label will come to the latest candle (3rd most – as the pattern is detected reliably only on the completion of the 3rd final candle).
Of course, any program can not eliminate your trained eyes and brain to capture the patterns. But we have provided sufficient knobs to adjust various parameters to tweak the candle-pattern detection. Such as Strict Inside Candle(Harami) Boolean knob where the whole current candle including wicks will be inside the body part of the previous big candle. For non-strict mode, the current candle just inside the previous candle, possibly by wicks.
To make it better usable, for every such knobs (which are not obvious) we have added user-friendly tooltip (just mouse hover the question mark (?) besides the control/switch). There are plenty of it.
Volume
Here we have a rudimentary (yet effective) way to judge the volumes.
We find out the Volume Weighted Moving Average (VMWA) of the 20-period (default, but customizable) and the latest volume. If the latest volume is more than the 20 period vwma, we just add a grey diamond on the top of the candle to denote it’s attracting volumes. Of course, we provide a Weight coefficient (default is set to 1). So if the current bar’s volume on bar’s completion is more than the 20 period volume vmwa times the weigh-cofficient, we mark it with a tiny grey diamond.
Points to be noted:
In all places we mark the indication only on the completion of the bar (technically speaking we have checks, as far as possible, with barstate.isconfirmed). However, if you wish, you can turn it off for Candlestick (as some experts may want to check candlestick on the real time, even before the closing of bars).
In case if you see the chart looks cluttered (because of many information, specially in smaller timeframes like 5 min), there are controls given in the settings to toggle each and every features.
By default, we turn off Doji candles (all 3 types of Doji’s – normal, Gravestone & Dragonfly) as they are mainly indecision. However, you can toggle it to turn it on.
It does not give you any Buy/Sell call. The interpretation it does not have.
Why?
What’s unique in it?
As we already mentioned our intention is to include Price (in forms of Support / Resistance), Volume and Action (sentiments in terms of Candlestick patterns) into a single place. And so far, to the best of our knowledge, we could not come across a single indicator provides all of these.
There were works available to determine the RSI based support / resistance zones. Those are great piece works at that time (lets say 3 years back when PineScript was in earlier versions). To the best of our knowledge those does not cover up finding out the lowest / highest point of RSI and the corresponding price to get the simplistic and distinct support/resistance lines.
We have the intuitive support/resistance strength included which we could not found out in current set of available indicators.
To the best of our knowledge, there seems no indicator can detect 3-candle patterns which are extremely popular to detect trend reversals (such as Morning Star or Evening Star). Moreover for the multi-candle patterns we are grouping the candles part of the pattens (2-candles or 3-candles) using a dotted rectangle such that it’s visually clearly (and a well educative material for Price-Action learners also).
Mentions:
There are many works which inspire us along the way. Honestly: we sometimes forgot which all indicators we experimented with. We are sincerely apologetic in case we forgot to mention. A few note-worthy:
There is an indicator from user “repo32” named as “Candlestick Patterns Identified (updated 3/11/15)”. (We could not be able to contact “repo32”). We are inspired from his work that it’s feasible to detect Candlestick patterns.
There is an awesome work done by “RSI Based Automatic Demand and Supply” by user “shtcoinr”. The idea of consulting multiple RSI levels to find out the demand/supply zone we inspired from him. (We did contact “shtcoinr” and got his kind permission to use the concept.)
We are greatly thankful to these abovementioned wizards for their pioneering a-prior work in this front.
And of course, this TradingView platform to provide this abstraction, facilitates and felicitates collaborative contributions.
Ultimately, what’s for you?
That’s the main question. What’s for you?
Price-action comprises of following 3 tasks (at least):
Draw support/resistance lines in the chart.
Once price reaches at the support/resistance line, you fervently look out the candles’ formation to mentally map to the candle patterns. Your aim is divine: You want to judge if the price-action will continue or take a rejection/reversal.
Then you double-confirm with the volume (in a non-overlaid chart below).
Finally take a trade.
For a price-action newbie or seasoned, expert practitioner, you must be doing all the above tasks regularly and manually, in a mechanical, mundane way. There come the humanly subjectivity & the inevitable emotions . This indicator, being a piece of program/code in PineScript latest version v5 , eliminates (or at least, reduces to a great extend) that subjectivity & emotions out of the way of decision making . Thus resulting better yield.
Of course, you can argue that you draw slanted trend lines also. We recommend an already existing indicator by user LuxAlgo named as “Trendlines with Breaks ”, if you wish so.
Disclaimer:
This piece of software does not come up with any warrantee or any rights of not changing it over the future course of time.
We are not responsible for any trading/investment decision you are taking out of the outcome of this indicator.
Happy trading.

Simple LevelsSimple Level provides a (you guessed it) simple user to user level sharing experience, with less boxes, less formatting, and less hassle.
Simply insert your levels into the input box, separated by commas. That's it.
Example: 1,2,3,4,5
The Simple Levels indicator will automatically color your lines based on their position to the current close price.
If the level is crossed, the level line will change color.
This indicator is intended for those who just want to skip filling out boxes or typing in a tricky format, and cut to the chase.
There are additional, nice-to-have settings as well for the "more" technically inclined; however, nothing too complicated.
Enjoy!

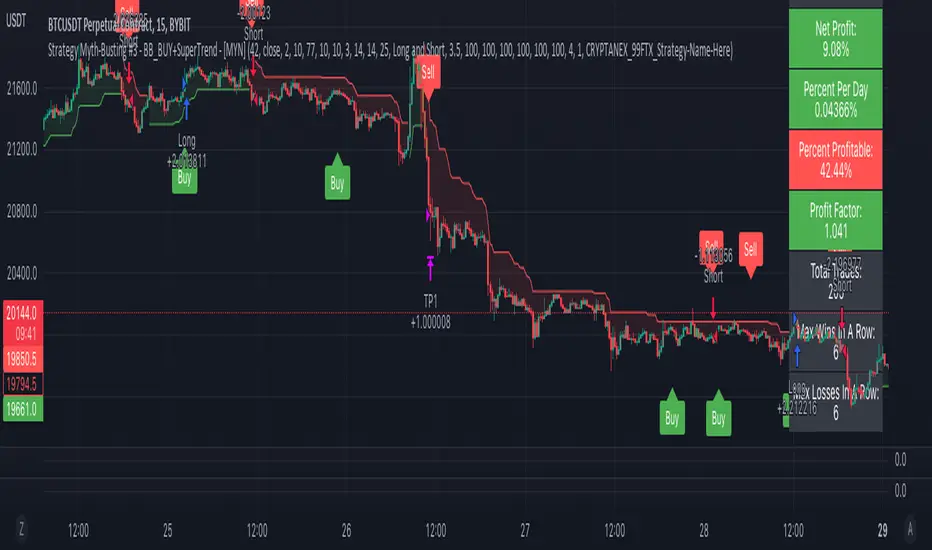
Strategy Myth-Busting #3 - BB_BUY+SuperTrend - [MYN]This is part of a new series we are calling "Strategy Myth-Busting" where we take open public manual trading strategies and automate them. The goal is to not only validate the authenticity of the claims but to provide an automated version for traders who wish to trade autonomously.
Our third one we are automating is one of the strategies from "The Best 3 Buy And Sell Indicators on Tradingview + Confirmation Indicators ( The Golden Ones ))" from "Online Trading Signals (Scalping Channel)". No formal backtesting was done by them so wanted to validate their claims.
If you know of or have a strategy you want to see myth-busted or just have an idea for one, please feel free to message me.
This strategy uses a combination of 2 open-source public indicators:
BB_Buy and Sell by guikroth (default settings)
SuperTrend from TradingView's Technicals (default settings)
Trading Rules
15 min candles
Long
Long condition when BB_BUY indicates buy signal and SuperTrend is green
Short
Short condition when BB_BUY indicates Sell signal and SuperTrend is red
T3 Velocity Candles [Loxx]T3 Velocity Candles is a candle coloring overlay that calculates its gradient coloring using T3 velocity.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.

T3 Striped [Loxx]Theory:
Although T3 is widely used, some of the details on how it is calculated are less known. T3 has, internally, 6 "levels" or "steps" that it uses for its calculation.
This version:
Instead of showing the final T3 value, this indicator shows those intermediate steps. This shows the "building steps" of T3 and can be used for trend assessment as well as for possible support / resistance values.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Alerts
Signals
Bar coloring
Loxx's Expanded Source Types
R-squared Adaptive T3 Ribbon Filled Simple [Loxx]R-squared Adaptive T3 Ribbon Filled Simple is a T3 ribbons indicator that uses a special implementation of T3 that is R-squared adaptive.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
What is R-squared Adaptive?
One tool available in forecasting the trendiness of the breakout is the coefficient of determination ( R-squared ), a statistical measurement.
The R-squared indicates linear strength between the security's price (the Y - axis) and time (the X - axis). The R-squared is the percentage of squared error that the linear regression can eliminate if it were used as the predictor instead of the mean value. If the R-squared were 0.99, then the linear regression would eliminate 99% of the error for prediction versus predicting closing prices using a simple moving average .
R-squared is used here to derive a T3 factor used to modify price before passing price through a six-pole non-linear Kalman filter.
Included:
Alerts
Signals
Loxx's Expanded Source Types
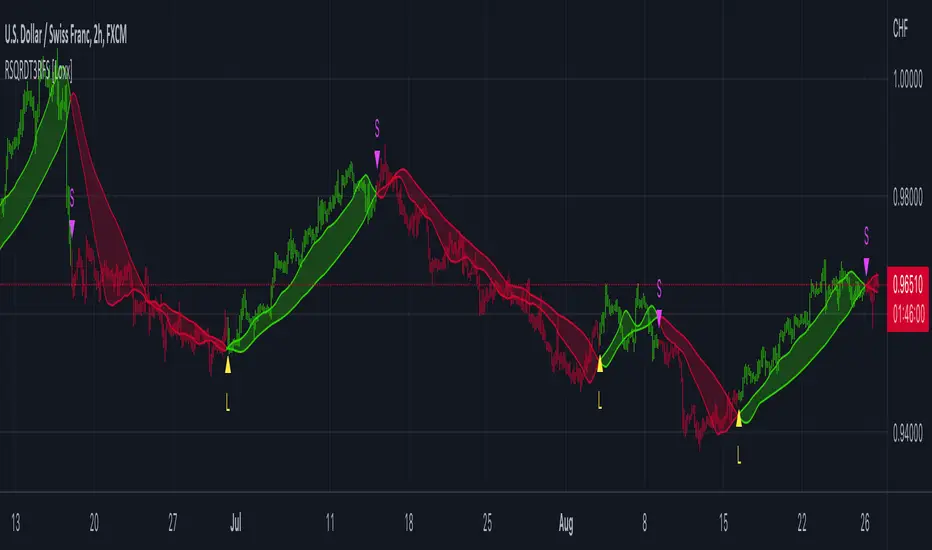
T3 Slope Variation [Loxx]T3 Slope Variation is an indicator that uses T3 moving average to calculate a slope that is then weighted to derive a signal.
The center line
The center line changes color depending on the value of the:
Slope
Signal line
Threshold
If the value is above a signal line (it is not visible on the chart) and the threshold is greater than the required, then the main trend becomes up. And reversed for the trend down.
Colors and style of the histogram
The colors and style of the histogram will be drawn if the value is at the right side, if the above described trend "agrees" with the value (above is green or below zero is red) and if the High is higher than the previous High or Low is lower than the previous low, then the according type of histogram is drawn.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Alets
Signals
Bar coloring
Loxx's Expanded Source Types
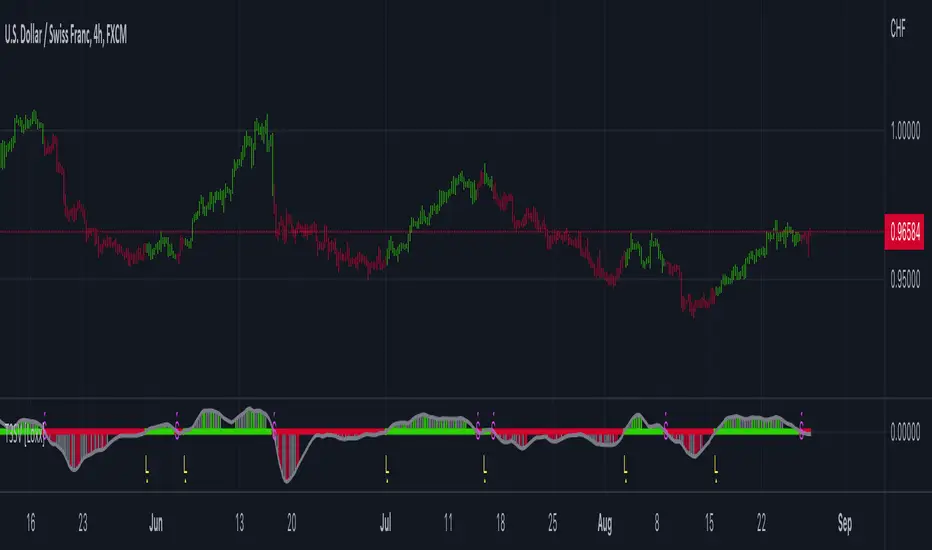
Multi T3 Slopes [Loxx]Multi T3 Slopes is an indicator that checks slopes of 5 (different period) T3 Moving Averages and adds them up to show overall trend. To us this, check for color changes from red to green where there is no red if green is larger than red and there is no red when red is larger than green. When red and green both show up, its a sign of chop.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Signals: long, short, continuation long, continuation short.
Alerts
Bar coloring
Loxx's expanded source types
T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering [Loxx]T3 Volatility Quality Index (VQI) w/ DSL & Pips Filtering is a VQI indicator that uses T3 smoothing and discontinued signal lines to determine breakouts and breakdowns. This also allows filtering by pips.***
What is the Volatility Quality Index ( VQI )?
The idea behind the volatility quality index is to point out the difference between bad and good volatility in order to identify better trade opportunities in the market. This forex indicator works using the True Range algorithm in combination with the open, close, high and low prices.
What are DSL Discontinued Signal Line?
A lot of indicators are using signal lines in order to determine the trend (or some desired state of the indicator) easier. The idea of the signal line is easy : comparing the value to it's smoothed (slightly lagging) state, the idea of current momentum/state is made.
Discontinued signal line is inheriting that simple signal line idea and it is extending it : instead of having one signal line, more lines depending on the current value of the indicator.
"Signal" line is calculated the following way :
When a certain level is crossed into the desired direction, the EMA of that value is calculated for the desired signal line
When that level is crossed into the opposite direction, the previous "signal" line value is simply "inherited" and it becomes a kind of a level
This way it becomes a combination of signal lines and levels that are trying to combine both the good from both methods.
In simple terms, DSL uses the concept of a signal line and betters it by inheriting the previous signal line's value & makes it a level.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Signals
Alerts
Related indicators
Zero-line Volatility Quality Index (VQI)
Volatility Quality Index w/ Pips Filtering
Variety Moving Average Waddah Attar Explosion (WAE)
***This indicator is tuned to Forex. If you want to make it useful for other tickers, you must change the pip filtering value to match the asset. This means that for BTC, for example, you likely need to use a value of 10,000 or more for pips filter.

T3 PPO [Loxx]T3 PPO is a percentage price oscillator indicator using T3 moving average. This indicator is used to spot reversals. Dark red is upward price exhaustion, dark green is downward price exhaustion.
What is Percentage Price Oscillator (PPO)?
The percentage price oscillator (PPO) is a technical momentum indicator that shows the relationship between two moving averages in percentage terms. The moving averages are a 26-period and 12-period exponential moving average (EMA).
The PPO is used to compare asset performance and volatility, spot divergence that could lead to price reversals, generate trade signals, and help confirm trend direction.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Mark FVGsMark FVGs is marking FVG (stands for Fair Value Gap, other name is Imbalance or IMB) on your chart so that you can instantly detect them
It supports:
- marking bullish and bearish partly filled or unfilled FVGs of the current timeframe
- marking bullish and bearish already filled FVGs of the current timeframe
- marking bullish and bearish FVGs of the any 4 timeframes on your current timeframe
technically it re-builds them on the last bar or as soon as new realtime bar is updated. it looks with 1k bars back to find the nearest specific number of FGVs
Adjustments:
- changing the maximum number of FVGs to display.
- changing the color of FVG area
- displaying already filled FVG of the current time frame
- changing the mode of displaying area it can either extended or fixed width
- displaying labels of other time frame FVGs

Mark LevelsMark Levels is marking liquidity pools by drawing lines on their pivots and labelling them so that you can instantly detect them on your realtime chart
It supports:
- marking previous and current day lows and highs
- marking previous and current week lows and highs
- marking previous and current month lows and highs
- marking equal lows and highs
technically it re-builds them on the last bar or as soon as new realtime bar is updated. it looks with 1k bars back to find higher timeframe ranges and find lows and highs there
Adjustments:
- changing the line style of the group
- changing the lines color and the labels on the groups
- currently pools are split on 2 groups Period Liquidity and Equal Pivots Liquidity.
PrasiGanFanFibntroduction
This is a combination of Fibonacci and Gann fan /retracements.
The script can automatically draw as many:
Fibonacci Retracements
Fibonacci Fan
Gann Retracements
Gann Fan
as the user requires on the chart. Each level set or fan consists of 7 lines based on the most important ratios of Fibonacci/ Gann .
Basics
What are Fibonacci retracements?
Fibonacci retracement levels are horizontal lines that indicate where support and resistance are likely to occur. They stem from Fibonacci’s sequence. Each level is associated with a percentage which is how much of a prior move the price has retraced. The Fibonacci retracement levels are 23.6%, 38.2%, 61.8%, and 78.6%. While not officially a Fibonacci ratio, 50% is also used. The indicator is useful because it can be drawn between any two significant price points, such as a high and a low. The indicator will then create the levels between those two points.
What are Gann retracements?
A developer of technical analysis and trading was W.D. Gann . Gann theory expects a normal retracement of 50 percent. This means that under normal selling pressure, the stock price will decline half the amount of its most recent rise, and vice versa. It also suggests that retracements occur at the halfway point of a move, such as 25 percent (half of 50 percent), 12.5 percent (half of 25 percent), and so on.
What is Fibonacci fan?
Fibonacci fan is a set of sequential trend lines drawn from a trough or peak through a set of points dictated by Fibonacci retracements. The first step to create it is to draw a trend line covering the local lowest and highest prices of a security. To reach retracement levels, the trader divides the difference in price at the low and high end by ratios determined by the Fibonacci series. The lines formed by connecting the starting point for the base trend line and each retracement level create the Fibonacci fan.
What is Gann fan?
A Gann fan consists of a series of lines called Gann angles. These angles are superimposed over a price chart to show potential support and resistance levels. The resulting image is supposed to help technical analysts predict price changes. Gann believed the 45-degree angle to be most important, but the Gann fan also draws angles at degrees like 75, 63.75, 26.25 and 15. The Gann fan originates at a low or high point. The resulting lines show areas of potential future support and resistance . The 45-degree line is known as the 1:1 line because the price will rise or fall at a 45-degree angle when the price moves up/down one unit for each unit of time. All other lines in the Gann fan are drawn above and below the 1:1 line. The other angles are associated with 2:1, 3:1, 4:1, 8:1 and 1:8, 1:4, 1:3, and 1:2 time-to-price moves.
Challenges
The most of the time I dedicated to writing this script has been spent on handling these problems:
1. Finding Local Highest/Lowest Prices
In order to draw Fibonacci and Gann fan /retracements, it's necessary to find local highest and lowest price points (Extrema) on the chart. As this could be so challenging, most traders and coders draw the lines covering the low and high prices over a given period of time or a limited number of bars back instead. I already wrote an indicator using this approach (Auto Fibonacci Combo).
In this new script I tried to find the exact highest and lowest prices based on this idea that: if a high point is formed lower than previous high which was after a lowest point, then that previous one was the local highest point, and vice versa if a low point is formed higher than previous low which was after a highest point, then that previous one was the local lowest point. So logically an extremum price on the chart won't be found until the next high/low point is formed.
2. Finding Proper Chart Scale for Gann Fan
Based on the theory, Gann angles are sensitive to the chart price scale and in order to have the right angles, the chart must be made with the proper scale. J.A. Hyerczyk in his book "Pattern, Price & Time - Using Gann Theory in Technical Analysis" suggests that the easiest way to determine the scale of a market is by taking the difference between top-to-top and bottom-to-bottom and dividing it by the time it took the market to move from top to top and bottom to bottom.
Thus on a properly constructed chart, the basic equation for calculating Gann angles is: Price * Time.
3. Drawing Fans and Relocating Fan Labels at Each New Bar in Pine (A Programming-Related Subject)
To do this, I used linear equations and line slopes. Of course it was so complicated and exhausting, but finally I overcame that thanks to my genius cousin.
Settings and Usage
By default, the script shows detected extremum points plus 1 Fibonacci fan, 1 Gann fan , 1 set of Fibonacci retracements and no Gann retracements on the chart. All of these could be changed in the indicator settings beside the color and transparency of each line.
Feel free to use this and send me your thoughts!
Ultimate Oscillator + DivergencesUltimate Oscillator (UO) + Divergences + Alerts + Lookback periods.
This version of the Ultimate Oscillator adds the following 3 additional features to the stock UO by Tradingview:
- Optional divergence lines drawn directly onto the oscillator.
- Configurable alerts to notify you when divergences occur.
- Configurable lookback periods to fine tune the divergences drawn in order to suit different trading styles and timeframes.
This indicator adds additional features onto the stock Ultimate Oscillator by Tradingview, whose core calculations remain unchanged. Namely the configurable option to automatically, quickly and clearly draw divergence lines onto the oscillator for you as they occur, with minimal delay. It also has the addition of unique alerts, so you can be notified when divergences occur without spending all day watching the charts. Furthermore, this version of the Ultimate Oscillator comes with configurable lookback periods, which can be configured in order to adjust the sensitivity of the divergences, in order to suit shorter or higher timeframe trading approaches.
The Ultimate Oscillator
Tradingview describes the Ultimate Oscillator as follows:
“The Ultimate Oscillator indicator (UO) indicator is a technical analysis tool used to measure momentum across three varying timeframes. The problem with many momentum oscillators is that after a rapid advance or decline in price, they can form false divergence trading signals. For example, after a rapid rise in price, a bearish divergence signal may present itself, however price continues to rise. The ultimate Oscillator attempts to correct this by using multiple timeframes in its calculation as opposed to just one timeframe which is what is used in most other momentum oscillators.”
More information on the history, use cases and calculations of the Ultimate Oscillator can be found here: www.tradingview.com
What are divergences?
Divergence is when the price of an asset is moving in the opposite direction of a technical indicator, such as an oscillator, or is moving contrary to other data. Divergence warns that the current price trend may be weakening, and in some cases may lead to the price changing direction.
There are 4 main types of divergence, which are split into 2 categories;
regular divergences and hidden divergences . Regular divergences indicate possible trend reversals, and hidden divergences indicate possible trend continuation.
Regular bullish divergence: An indication of a potential trend reversal, from the current downtrend, to an uptrend.
Regular bearish divergence: An indication of a potential trend reversal, from the current uptrend, to a downtrend.
Hidden bullish divergence: An indication of a potential uptrend continuation.
Hidden bearish divergence: An indication of a potential downtrend continuation.
Setting alerts.
With this indicator you can set alerts to notify you when any/all of the above types of divergences occur, on any chart timeframe you choose.
Configurable lookback values.
You can adjust the default lookback values to suit your prefered trading style and timeframe. If you like to trade a shorter time frame, lowering the default lookback values will make the divergences drawn more sensitive to short term price action.
How do traders use divergences in their trading?
A divergence is considered a leading indicator in technical analysis, meaning it has the ability to indicate a potential price move in the short term future.
Hidden bullish and hidden bearish divergences, which indicate a potential continuation of the current trend are sometimes considered a good place for traders to begin, since trend continuation occurs more frequently than reversals, or trend changes.
When trading regular bullish divergences and regular bearish divergences, which are indications of a trend reversal, the probability of it doing so may increase when these occur at a strong support or resistance level. A common mistake new traders make is to get into a regular divergence trade too early, assuming it will immediately reverse, but these can continue to form for some time before the trend eventually changes, by using forms of support or resistance as an added confluence, such as when price reaches a moving average, the success rate when trading these patterns may increase.
Typically, traders will manually draw lines across the swing highs and swing lows of both the price chart and the oscillator to see whether they appear to present a divergence, this indicator will draw them for you, quickly and clearly, and can notify you when they occur.
Disclaimer : This script includes code from the stock UO by Tradingview as well as the RSI divergence indicator.
Stoch/RSI with EMA50 Cross & HHLLA hybrid but simple indicator that plots 4 strategies in one pane .
1) RSI Indicator
2) Stoch RSI
3) EMA50 Cross (To determine direction in current timeframe)
4) Higher Highs & Lower Lows to analyze the trend and break of trend
The relative strength index (RSI) is a momentum indicator used in technical analysis. It is displayed as an oscillator (a line graph) on a scale of zero to 100. When the RSI indicator crosses 30 on the RSI chart, it is a bullish sign and when it crosses 70, it is a bearish sign.
The Stochastic RSI (StochRSI) is also a momentum indicator used in technical analysis. It is displayed as an oscillator (a line graph) on a scale of zero to 100. When the StochRSI indicator crosses 20 on the RSI chart, it is a bullish sign and when it crosses 80, it is a bearish sign.
The EMA50Cross denotes two cases in the script:
a) A crossover of CMP on the EMA50 is highlighted by a green bar signals a possible bullish trend
b) A crossunder of CMP on the EMA50 is highlighted by a red bar signals a possible bearish trend
The HHLL is denoted by mneumonics HH, HL,LH, LL. A combination of HHs and HLs denotes a uptrend while the combination of LLs and LHs denoted a downtrend
The current script should be used in confluence of other trading strategies and not in isolation.
Scenario 1:
If a EMA50Cross over bar (GREEN) is highlighted with the StochRSI below 20 and the given script is plotting HHs and HLs, we are most likely in a bullish trend for the given timeframe and a long can be initiated in confluence with other trading strategies used by the user. The RSI signal may now be utilized to determine a good range of entry/exit.
Scenario 2:
If a EMA50Cross under bar (RED) is highlighted with the StochRSI above 80 and the given script is plotting LLs and LHs, we are most likely in a bearish trend for the given timeframe and a short can be initiated in confluence with other trading strategies used by the user. The RSI signal may now be utilized to determine a good range of entry/exit.
Disclaimer:
The current script should be used in confluence with other trading strategies and not in isolation. The scripts works best on 4H and 1D Timeframes and should be used with caution on lower timeframes.
This indicator is not intended to give exact entry or exit points for a trade but to provide a general idea of the trend & determine a good range for entering or exiting the trade. Please DYOR
Credit & References:
This script uses the default technical analysis reference library provided by PineScript (denoted as ta)
VIDYA Trend StrategyOne of the most common messages I get is people reaching out asking for quantitative strategies that trade cryptocurrency. This has compelled me to write this script and article, to help provide a quantitative/technical perspective on why I believe most strategies people write for crypto fail catastrophically, and how one might build measures within their strategies that help reduce the risk of that happening. For those that don't trade crypto, know that these approaches are applicable to any market.
I will start off by qualifying up that I mainly trade stocks and ETFs, and I believe that if you trade crypto, you should only be playing with money you are okay with losing. Most published crypto strategies I have seen "work" when the market is going up, and fail catastrophically when it is not. There are far more people trying to sell you a strategy than there are people providing 5-10+ year backtest results on their strategies, with slippage and commissions included, showing how they generated alpha and beat buy/hold. I understand that this community has some really talented people that can create some really awesome things, but I am saying that the vast majority of what you find on the internet will not be strategies that create alpha over the long term.
So, why do so many of these strategies fail?
There is an assumption many people make that cryptocurrency will act just like stocks and ETFs, and it does not. ETF returns have more of a Gaussian probability distribution. Because of this, ETFs have a short term mean reverting behavior that can be capitalized on consistently. Many technical indicators are built to take advantage of this on the equities market. Many people apply them to crypto. Many of those people are drawn down 60-70% right now while there are mean reversion strategies up YTD on equities, even though the equities market is down. Crypto has many more "tail events" that occur 3-4+ standard deviations from the mean.
There is a correlation in many equities and ETF markets for how long an asset continues to do well when it is currently doing well. This is known as momentum, and that correlation and time-horizon is different for different assets. Many technical indicators are built based on this behavior, and then people apply them to cryptocurrency with little risk management assuming they behave the same and and on the same time horizon, without pulling in the statistics to verify if that is actually the case. They do not.
People do not take into account the brokerage commissions and slippage. Brokerage commissions are particularly high with cryptocurrency. The irony here isn't lost to me. When you factor in trading costs, it blows up most short-term trading strategies that might otherwise look profitable.
There is an assumption that it will "always come back" and that you "HODL" through the crash and "buy more." This is why Three Arrows Capital, a $10 billion dollar crypto hedge fund is now in bankruptcy, and no one can find the owners. This is also why many that trade crypto are drawn down 60-70% right now. There are bad risk practices in place, like thinking the martingale gambling strategy is the same as dollar cost averaging while also using those terms interchangeably. They are not the same. The 1st will blow up your trade account, and the 2nd will reduce timing risk. Many people are systematically blowing up their trade accounts/strategies by using martingale and calling it dollar cost averaging. The more risk you are exposing yourself too, the more important your risk management strategy is.
There is an odd assumption some have that you can buy anything and win with technical/quantitative analysis. Technical analysis does not tell you what you should buy, it just tells you when. If you are running a strategy that is going long on an asset that lost 80% of its value in the last year, then your strategy is probably down. That same strategy might be up on a different asset. One might consider a different methodology on choosing assets to trade.
Lastly, most strategies are over-fit, or curve-fit. The more complicated and more parameters/settings you have in your model, the more likely it is just fit to historical data and will not perform similar in live trading. This is one of the reasons why I like simple models with few parameters. They are less likely to be over-fit to historical data. If the strategy only works with 1 set of parameters, and there isn't a range of parameters around it that create alpha, then your strategy is over-fit and is probably not suitable for live trading.
So, what can I do about all of this!?
I created the VIDYA Trend Strategy to provide an example of how one might create a basic model with a basic risk management strategy that might generate long term alpha on a volatile asset, like cryptocurrency. This is one (of many) risk management strategies that can reduce the volatility of your returns when trading any asset. I chose the Variable Index Dynamic Average (VIDYA) for this example because it's calculation filters out some market noise by taking into account the volatility of the underlying asset. I chose a trend following strategy because regressions are capturing behaviors that are not just specific to the equities market.
The more volatile an asset, the more you have to back-off the short term price movement to effectively trend-follow it. Otherwise, you are constantly buying into short term trends that don't represent the trend of the asset, then they reverse and loose money. This is why I am applying a trend following strategy to a 4 hour chart and not a 4 minute chart. It is also important to note that following these long term trends on a volatile asset exposes you to additional risk. So, how might one mitigate some of that risk?
One of the ways of reducing timing risk is scaling into a trade. This is different from "doubling down" or "trippling down." It is really a basic application of dollar cost averaging to reduce timing risk, although DCA would typically happen over a longer time period. If it is really a trend you are following, it will probably still be a trend tomorrow. Trend following strategies have lower win rates because the beginning of a trend often reverses. The more volatile the asset, the more likely that is to happen. However, we can reduce risk of buying into a reversal by slowly scaling into the trend with a small % of equity per trade.
Our example "VIDYA Trend Strategy" executes this by looking at a medium-term, volatility adjusted trend on a 4 hour chart. The script scales into it with 4% of the account equity every 4-hours that the trend is still up. This means you become fully invested after 25 trades/bars. It also means that early in the trade, when you might be more likely to experience a reversal, most of your account equity is not invested and those losses are much smaller. The script sells 100% of the position when it detects a trend reversal. The slower you scale into a trade, the less volatile your equity curve will be. This model also includes slippage and commissions that you can adjust under the "settings" menu.
This fundamental concept of reducing timing risk by scaling into a trade can be applied to any market.
Disclaimer: This is not financial advice. Open-source scripts I publish in the community are largely meant to spark ideas that can be used as building blocks for part of a more robust trade management strategy. If you would like to implement a version of any script, I would recommend making significant additions/modifications to the strategy & risk management functions. If you don’t know how to program in Pine, then hire a Pine-coder. We can help!

VHF-Adaptive T3 iTrend [Loxx]VHF-Adaptive T3 iTrend is an iTrend indicator with T3 smoothing and Vertical Horizontal Filter Adaptive period input. iTrend is used to determine where the trend starts and ends. You'll notice that the noise filter on this one is extreme. Adjust the period inputs accordingly to suit your take and your backtest requirements. This is also useful for scalping lower timeframes. Enjoy!
What is VHF Adaptive Period?
Vertical Horizontal Filter (VHF) was created by Adam White to identify trending and ranging markets. VHF measures the level of trend activity, similar to ADX DI. Vertical Horizontal Filter does not, itself, generate trading signals, but determines whether signals are taken from trend or momentum indicators. Using this trend information, one is then able to derive an average cycle length.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included
Bar coloring
Alerts
Signals
Loxx's Expanded Source Types
CFB-Adaptive CCI w/ T3 Smoothing [Loxx]CFB-Adaptive CCI w/ T3 Smoothing is a CCI indicator with adaptive period inputs and T3 smoothing. Jurik's Composite Fractal Behavior is used to created dynamic period input.
What is Composite Fractal Behavior ( CFB )?
All around you mechanisms adjust themselves to their environment. From simple thermostats that react to air temperature to computer chips in modern cars that respond to changes in engine temperature, r.p.m.'s, torque, and throttle position. It was only a matter of time before fast desktop computers applied the mathematics of self-adjustment to systems that trade the financial markets.
Unlike basic systems with fixed formulas, an adaptive system adjusts its own equations. For example, start with a basic channel breakout system that uses the highest closing price of the last N bars as a threshold for detecting breakouts on the up side. An adaptive and improved version of this system would adjust N according to market conditions, such as momentum, price volatility or acceleration.
Since many systems are based directly or indirectly on cycles, another useful measure of market condition is the periodic length of a price chart's dominant cycle, (DC), that cycle with the greatest influence on price action.
The utility of this new DC measure was noted by author Murray Ruggiero in the January '96 issue of Futures Magazine. In it. Mr. Ruggiero used it to adaptive adjust the value of N in a channel breakout system. He then simulated trading 15 years of D-Mark futures in order to compare its performance to a similar system that had a fixed optimal value of N. The adaptive version produced 20% more profit!
This DC index utilized the popular MESA algorithm (a formulation by John Ehlers adapted from Burg's maximum entropy algorithm, MEM). Unfortunately, the DC approach is problematic when the market has no real dominant cycle momentum, because the mathematics will produce a value whether or not one actually exists! Therefore, we developed a proprietary indicator that does not presuppose the presence of market cycles. It's called CFB (Composite Fractal Behavior) and it works well whether or not the market is cyclic.
CFB examines price action for a particular fractal pattern, categorizes them by size, and then outputs a composite fractal size index. This index is smooth, timely and accurate
Essentially, CFB reveals the length of the market's trending action time frame. Long trending activity produces a large CFB index and short choppy action produces a small index value. Investors have found many applications for CFB which involve scaling other existing technical indicators adaptively, on a bar-to-bar basis.
What is Jurik Volty used in the Juirk Filter?
One of the lesser known qualities of Juirk smoothing is that the Jurik smoothing process is adaptive. "Jurik Volty" (a sort of market volatility ) is what makes Jurik smoothing adaptive. The Jurik Volty calculation can be used as both a standalone indicator and to smooth other indicators that you wish to make adaptive.
What is the Jurik Moving Average?
Have you noticed how moving averages add some lag (delay) to your signals? ... especially when price gaps up or down in a big move, and you are waiting for your moving average to catch up? Wait no more! JMA eliminates this problem forever and gives you the best of both worlds: low lag and smooth lines.
Ideally, you would like a filtered signal to be both smooth and lag-free. Lag causes delays in your trades, and increasing lag in your indicators typically result in lower profits. In other words, late comers get what's left on the table after the feast has already begun.
What is the T3 moving average?
Better Moving Averages Tim Tillson
November 1, 1998
Tim Tillson is a software project manager at Hewlett-Packard, with degrees in Mathematics and Computer Science. He has privately traded options and equities for 15 years.
Introduction
"Digital filtering includes the process of smoothing, predicting, differentiating, integrating, separation of signals, and removal of noise from a signal. Thus many people who do such things are actually using digital filters without realizing that they are; being unacquainted with the theory, they neither understand what they have done nor the possibilities of what they might have done."
This quote from R. W. Hamming applies to the vast majority of indicators in technical analysis . Moving averages, be they simple, weighted, or exponential, are lowpass filters; low frequency components in the signal pass through with little attenuation, while high frequencies are severely reduced.
"Oscillator" type indicators (such as MACD , Momentum, Relative Strength Index ) are another type of digital filter called a differentiator.
Tushar Chande has observed that many popular oscillators are highly correlated, which is sensible because they are trying to measure the rate of change of the underlying time series, i.e., are trying to be the first and second derivatives we all learned about in Calculus.
We use moving averages (lowpass filters) in technical analysis to remove the random noise from a time series, to discern the underlying trend or to determine prices at which we will take action. A perfect moving average would have two attributes:
It would be smooth, not sensitive to random noise in the underlying time series. Another way of saying this is that its derivative would not spuriously alternate between positive and negative values.
It would not lag behind the time series it is computed from. Lag, of course, produces late buy or sell signals that kill profits.
The only way one can compute a perfect moving average is to have knowledge of the future, and if we had that, we would buy one lottery ticket a week rather than trade!
Having said this, we can still improve on the conventional simple, weighted, or exponential moving averages. Here's how:
Two Interesting Moving Averages
We will examine two benchmark moving averages based on Linear Regression analysis.
In both cases, a Linear Regression line of length n is fitted to price data.
I call the first moving average ILRS, which stands for Integral of Linear Regression Slope. One simply integrates the slope of a linear regression line as it is successively fitted in a moving window of length n across the data, with the constant of integration being a simple moving average of the first n points. Put another way, the derivative of ILRS is the linear regression slope. Note that ILRS is not the same as a SMA ( simple moving average ) of length n, which is actually the midpoint of the linear regression line as it moves across the data.
We can measure the lag of moving averages with respect to a linear trend by computing how they behave when the input is a line with unit slope. Both SMA (n) and ILRS(n) have lag of n/2, but ILRS is much smoother than SMA .
Our second benchmark moving average is well known, called EPMA or End Point Moving Average. It is the endpoint of the linear regression line of length n as it is fitted across the data. EPMA hugs the data more closely than a simple or exponential moving average of the same length. The price we pay for this is that it is much noisier (less smooth) than ILRS, and it also has the annoying property that it overshoots the data when linear trends are present.
However, EPMA has a lag of 0 with respect to linear input! This makes sense because a linear regression line will fit linear input perfectly, and the endpoint of the LR line will be on the input line.
These two moving averages frame the tradeoffs that we are facing. On one extreme we have ILRS, which is very smooth and has considerable phase lag. EPMA has 0 phase lag, but is too noisy and overshoots. We would like to construct a better moving average which is as smooth as ILRS, but runs closer to where EPMA lies, without the overshoot.
A easy way to attempt this is to split the difference, i.e. use (ILRS(n)+EPMA(n))/2. This will give us a moving average (call it IE /2) which runs in between the two, has phase lag of n/4 but still inherits considerable noise from EPMA. IE /2 is inspirational, however. Can we build something that is comparable, but smoother? Figure 1 shows ILRS, EPMA, and IE /2.
Filter Techniques
Any thoughtful student of filter theory (or resolute experimenter) will have noticed that you can improve the smoothness of a filter by running it through itself multiple times, at the cost of increasing phase lag.
There is a complementary technique (called twicing by J.W. Tukey) which can be used to improve phase lag. If L stands for the operation of running data through a low pass filter, then twicing can be described by:
L' = L(time series) + L(time series - L(time series))
That is, we add a moving average of the difference between the input and the moving average to the moving average. This is algebraically equivalent to:
2L-L(L)
This is the Double Exponential Moving Average or DEMA , popularized by Patrick Mulloy in TASAC (January/February 1994).
In our taxonomy, DEMA has some phase lag (although it exponentially approaches 0) and is somewhat noisy, comparable to IE /2 indicator.
We will use these two techniques to construct our better moving average, after we explore the first one a little more closely.
Fixing Overshoot
An n-day EMA has smoothing constant alpha=2/(n+1) and a lag of (n-1)/2.
Thus EMA (3) has lag 1, and EMA (11) has lag 5. Figure 2 shows that, if I am willing to incur 5 days of lag, I get a smoother moving average if I run EMA (3) through itself 5 times than if I just take EMA (11) once.
This suggests that if EPMA and DEMA have 0 or low lag, why not run fast versions (eg DEMA (3)) through themselves many times to achieve a smooth result? The problem is that multiple runs though these filters increase their tendency to overshoot the data, giving an unusable result. This is because the amplitude response of DEMA and EPMA is greater than 1 at certain frequencies, giving a gain of much greater than 1 at these frequencies when run though themselves multiple times. Figure 3 shows DEMA (7) and EPMA(7) run through themselves 3 times. DEMA^3 has serious overshoot, and EPMA^3 is terrible.
The solution to the overshoot problem is to recall what we are doing with twicing:
DEMA (n) = EMA (n) + EMA (time series - EMA (n))
The second term is adding, in effect, a smooth version of the derivative to the EMA to achieve DEMA . The derivative term determines how hot the moving average's response to linear trends will be. We need to simply turn down the volume to achieve our basic building block:
EMA (n) + EMA (time series - EMA (n))*.7;
This is algebraically the same as:
EMA (n)*1.7-EMA( EMA (n))*.7;
I have chosen .7 as my volume factor, but the general formula (which I call "Generalized Dema") is:
GD (n,v) = EMA (n)*(1+v)-EMA( EMA (n))*v,
Where v ranges between 0 and 1. When v=0, GD is just an EMA , and when v=1, GD is DEMA . In between, GD is a cooler DEMA . By using a value for v less than 1 (I like .7), we cure the multiple DEMA overshoot problem, at the cost of accepting some additional phase delay. Now we can run GD through itself multiple times to define a new, smoother moving average T3 that does not overshoot the data:
T3(n) = GD ( GD ( GD (n)))
In filter theory parlance, T3 is a six-pole non-linear Kalman filter. Kalman filters are ones which use the error (in this case (time series - EMA (n)) to correct themselves. In Technical Analysis , these are called Adaptive Moving Averages; they track the time series more aggressively when it is making large moves.
Included:
Bar coloring
Signals
Alerts
