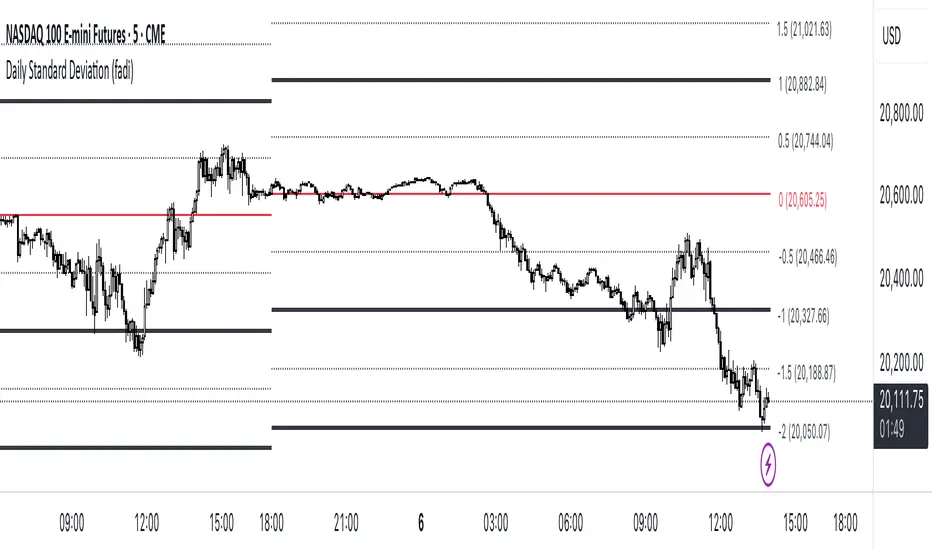
Daily Standard Deviation (fadi)The Daily Standard Deviation indicator uses standard deviation to map out daily price movements. Standard deviation measures how much prices stray from their average—small values mean steady trends, large ones mean wild swings. Drawing from up to 20 years of data, it plots key levels using customizable Fibonacci lines tied to that standard deviation, giving traders a snapshot of typical price behavior.
These levels align with a bell curve: about 68% of price moves stay within 1 standard deviation, 95% within roughly 2, and 99.7% within roughly 3. When prices break past the 1 StDev line, they’re outliers—only 32% of moves go that far. Prices often snap back to these lines or the average, though the reversal might not happen the same day.
How Traders Use It
If prices surge past the 1 StDev line, traders might wait for momentum to fade, then trade the pullback to that line or the average, setting a target and stop.
If prices dip below, they might buy, anticipating a bounce—sometimes a day or two later. It’s a tool to spot overstretched prices likely to revert and/or measure the odds of continuation.
Settings
Open Hour: Sets the trading day’s start (default: 18:00 EST).
Show Levels for the Last X Days: Displays levels for the specified number of days.
Based on X Period: Number of days to calculate standard deviation (e.g., 20 years ≈ 5,040 days). Larger periods smooth out daily level changes.
Mirror Levels on the Other Side: Plots symmetric positive and negative levels around the average.
Fibonacci Levels Settings: Defines which levels and line styles to show. With mirroring, negative values aren’t needed.
Overrides: Lets advanced users input custom standard deviations for specific tickers (e.g., NQ1! at 0.01296).
Standard Deviation
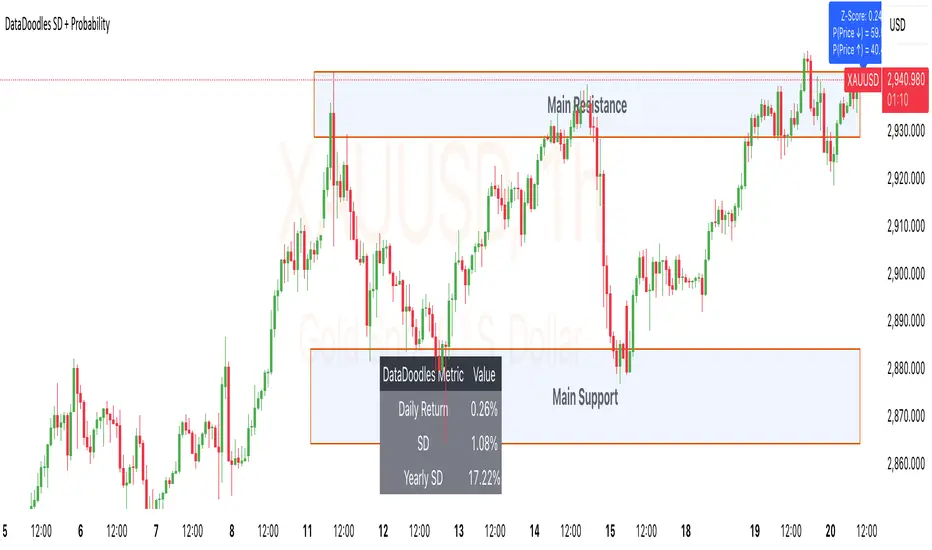
DataDoodles SD + ProbabilityDataDoodles SD + Probability
Overview:
The “DataDoodles SD + Probability” indicator is designed to provide traders with a statistical edge by leveraging standard deviation and probability metrics. This advanced tool calculates the annualized standard deviation, Z-score, and probability of price movements, offering insights into potential market direction with customizable alert thresholds.
Key Features:
1. Annualized Standard Deviation (Volatility) Calculation:
• Uses a user-defined period to compute the rolling standard deviation of daily returns.
• Annualizes the volatility, giving a clear picture of expected price fluctuations.
2. Probability of Price Movement:
• Calculates the probability of price moving up or down using a corrected Z-Score.
• Displays the probability percentage for both upward and downward movements.
3. Dynamic Alerts:
• Configurable alerts for upward and downward price movement probabilities.
• Receive alerts when the probability exceeds user-defined thresholds.
4. Projections and Visuals:
• Plots projected high and low price levels based on annualized volatility.
• Displays Z-Score and probability metrics on the chart for quick reference.
5. Comprehensive Data Table:
• Bottom-center table displays key metrics:
• Daily Return
• Standard Deviation (SD)
• Annualized Standard Deviation (Yearly SD)
User Inputs:
• Annualization Period: Set the time frame for volatility annualization (Default: 252 days).
• SD Period: Define the rolling window for calculating standard deviation (Default: 252 days).
• Alert Probability Up/Down: Customize the probability thresholds for alerts (Default: 90%).
How It Works:
• Data Request and Calculation:
• Uses daily close prices to ensure consistent timeframe calculations.
• Calculates daily returns and annualizes the volatility using the square root of the time frame.
• Probability Computation:
• Employs a normal distribution CDF approximation to compute the probability of upward and downward price movements.
• Adjusts probabilities based on Z-Score to ensure accuracy.
• High and Low Projections:
• Utilizes the annualized volatility to estimate high and low price projections for the year.
• Visual Indicators and Alerts:
• Plots projected high (green) and low (red) levels on the chart.
• Displays Z-Score, probability percentages, and dynamically updates a statistics table.
Use Cases:
• Trend Analysis: Identify high-probability market movements using the probability metrics.
• Volatility Insights: Understand annualized volatility to gauge market risk and potential price ranges.
• Strategic Trading Decisions: Set alerts for high-probability scenarios to optimize entry and exit points.
Why Use “DataDoodles SD + Probability”?
This indicator provides a powerful combination of statistical analysis and visual representation. It empowers traders with:
• Quantitative Edge: By leveraging probability metrics and standard deviation, users can make informed trading decisions.
• Risk Management: Annualized volatility projections help in setting realistic stop-loss and take-profit levels.
• Actionable Alerts: Customizable probability alerts ensure users are notified of potential market moves, allowing proactive trading strategies.
Recommended Settings:
• Annualization Period: 252 (Ideal for daily data representing a trading year)
• SD Period: 252 (One trading year for consistent volatility calculations)
• Alert Probability: Set to 90% for conservative signals or lower for more frequent alerts.
Final Thoughts:
The “DataDoodles SD + Probability” indicator is a robust tool for traders looking to integrate statistical analysis into their trading strategies. It combines volatility measurement, probability calculations, and dynamic alerts to provide a comprehensive market overview.
Whether you’re a day trader or a long-term investor, this indicator can enhance your market insight and improve decision-making accuracy.
Disclaimer:
This indicator is a technical analysis tool designed for educational purposes. Past performance is not indicative of future results. Traders are encouraged to perform their own analysis and manage risk accordingly.
MTF- Standard Deviation ChannelWhat Is Standard Deviation?
Standard deviation is a statistical measurement that looks at how far individual points in a dataset are dispersed from the mean of that set. If data points are further from the mean, there is a higher deviation within the data set. It is calculated as the square root of the variance.
Key Takeaways:
Standard deviation measures the dispersion of a dataset relative to its mean.
It is calculated as the square root of the variance.
Standard deviation, in finance, is often used as a measure of the relative riskiness of an asset.
A volatile stock has a high standard deviation, while the deviation of a stable blue-chip stock is usually rather low.
Standard deviation is also used by businesses to assess risk, manage business operations, and plan cash flows based on seasonal changes and volatility.
Source: Investopedia
--------------- UPDATE ---------------
The deviation is calculated automatically. (via stdev function).
--
The targeted timeframe is available in the options (recalculation cycle).
--
If the selected security is a contract the number of days before expiration is automatically managed, otherwise it will use the 'default' options.
---------------------------------------

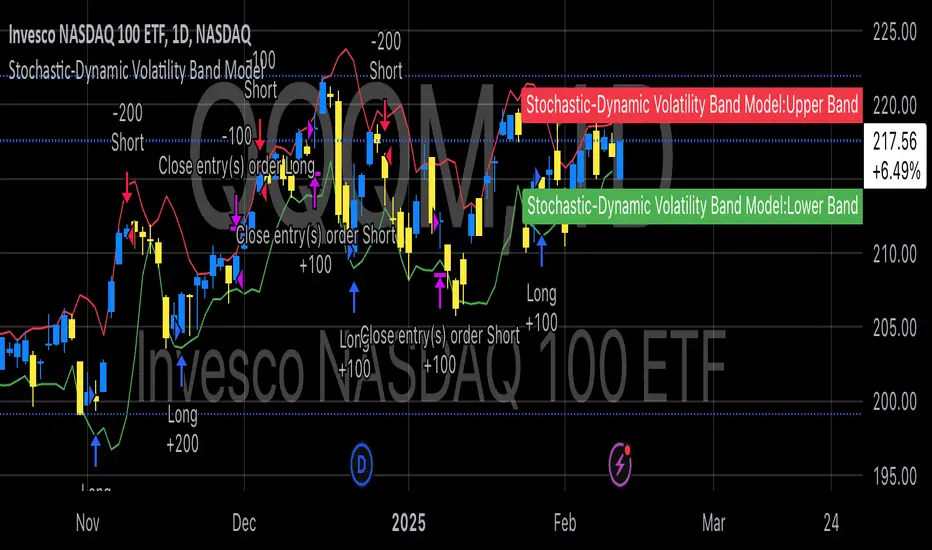
Stochastic-Dynamic Volatility Band ModelThe Stochastic-Dynamic Volatility Band Model is a quantitative trading approach that leverages statistical principles to model market volatility and generate buy and sell signals. The strategy is grounded in the concepts of volatility estimation and dynamic market regimes, where the core idea is to capture price fluctuations through stochastic models and trade around volatility bands.
Volatility Estimation and Band Construction
The volatility bands are constructed using a combination of historical price data and statistical measures, primarily the standard deviation (σ) of price returns, which quantifies the degree of variation in price movements over a specific period. This methodology is based on the classical works of Black-Scholes (1973), which laid the foundation for using volatility as a core component in financial models. Volatility is a crucial determinant of asset pricing and risk, and it plays a pivotal role in this strategy's design.
Entry and Exit Conditions
The entry conditions are based on the price’s relationship with the volatility bands. A long entry is triggered when the price crosses above the lower volatility band, indicating that the market may have been oversold or is experiencing a reversal to the upside. Conversely, a short entry is triggered when the price crosses below the upper volatility band, suggesting overbought conditions or a potential market downturn.
These entry signals are consistent with the mean reversion theory, which asserts that asset prices tend to revert to their long-term average after deviating from it. According to Poterba and Summers (1988), mean reversion occurs due to overreaction to news or temporary disturbances, leading to price corrections.
The exit condition is based on the number of bars that have elapsed since the entry signal. Specifically, positions are closed after a predefined number of bars, typically set to seven bars, reflecting a short-term trading horizon. This exit mechanism is in line with short-term momentum trading strategies discussed in literature, where traders capitalize on price movements within specific timeframes (Jegadeesh & Titman, 1993).
Market Adaptability
One of the key features of this strategy is its dynamic nature, as it adapts to the changing volatility environment. The volatility bands automatically adjust to market conditions, expanding in periods of high volatility and contracting when volatility decreases. This dynamic adjustment helps the strategy remain robust across different market regimes, as it is capable of identifying both trend-following and mean-reverting opportunities.
This dynamic adaptability is supported by the adaptive market hypothesis (Lo, 2004), which posits that market participants evolve their strategies in response to changing market conditions, akin to the adaptive nature of biological systems.
References:
Black, F., & Scholes, M. (1973). The Pricing of Options and Corporate Liabilities. Journal of Political Economy, 81(3), 637-654.
Bollinger, J. (1980). Bollinger on Bollinger Bands. Wiley.
Jegadeesh, N., & Titman, S. (1993). Returns to Buying Winners and Selling Losers: Implications for Stock Market Efficiency. Journal of Finance, 48(1), 65-91.
Lo, A. W. (2004). The Adaptive Markets Hypothesis: Market Efficiency from an Evolutionary Perspective. Journal of Portfolio Management, 30(5), 15-29.
Poterba, J. M., & Summers, L. H. (1988). Mean Reversion in Stock Prices: Evidence and Implications. Journal of Financial Economics, 22(1), 27-59.
STDEV Multi TimeFrame [Snowdex]STDEV Multi TimeFrame
The STDEV Multi TimeFrame indicator plots standard deviation levels (+1SD, +2SD, +3SD, -1SD, -2SD, -3SD) based on a user-selected timeframe (1D, 1W, 1M, etc.). It helps identify volatility, trend strength, and potential reversal zones using Bollinger Bands-style deviation calculations.
Key Features:
✅ Multi-Timeframe Selection – Choose any timeframe for STDEV calculations.
✅ Customizable Bollinger Bands – Select SMA, EMA, RMA, or WMA as the baseline.
✅ Color-Coded STDEV Levels – Fast (Green), Medium (Orange), Slow (Red).
✅ Non-Repainting & Accurate – Uses request.security() for precise data retrieval.
✅ Extended Lines & Labels – Clear trend monitoring with formatted values.
Use Cases:
📌 Detect trend direction & volatility.
📌 Identify overbought/oversold zones.
📌 Use as dynamic support/resistance levels.
🚀 Ideal for stocks, forex, crypto, and options trading! 🚀

Cypto Oscillator with Sortino-like VolatilityEnhanced Inverted Ultimate Oscillator with Sortino-like Volatility
This indicator combines the power of the Ultimate Oscillator with a unique Sortino-like volatility calculation to provide a comprehensive view of market dynamics. It's designed to help traders identify potential turning points and assess the risk associated with price movements.
**Core Components:**
* **Ultimate Oscillator (UO):** The UO is a momentum indicator that incorporates short, medium, and long-term price action to identify overbought and oversold conditions. This indicator inverts and normalizes the UO to a 0-10 scale, providing a clear view of momentum shifts.
* **Sortino-like Volatility:** Instead of a standard deviation, this indicator uses a downside deviation calculation. This focuses specifically on *negative* price movements, offering a more relevant measure of risk for most traders. By not penalizing upside volatility, it avoids giving false signals during strong bull runs. The downside deviation is scaled as a percentage of the closing price for cross-asset comparability.
* **Volatility Signal:** The inverted UO is multiplied by the downside deviation to create a combined volatility signal. This signal reflects both momentum and downside risk, providing a more nuanced market perspective.
**Key Features and Uses:**
* **Identifying Potential Turning Points:** Divergences between the UO and price action can signal potential trend reversals. Look for the UO to make higher lows while price makes lower lows (bullish divergence) or the UO to make lower highs while price makes higher highs (bearish divergence).
* **Assessing Downside Risk:** The Sortino-like volatility component helps traders gauge the potential for downside price swings. Higher volatility suggests greater risk.
* **Dynamic Volatility Thresholds:** The indicator includes adjustable upper and lower volatility thresholds, based on a moving average of the volatility signal. These thresholds can be used to identify periods of unusually high or low volatility.
* **Customizable Lookback Periods:** Traders can adjust the lookback periods for the UO and the standard deviation calculation to fine-tune the indicator to their specific trading style and market conditions.
* **Visualizations:** The indicator provides several visual aids, including:
* A histogram of the volatility signal, colored dynamically based on its relationship to the moving average of volatility. Red indicates volatility above the upper bound, orange between the bounds and green below the lower bound.
* A line plot of the volatility signal.
* An optional moving average of the volatility signal.
* Optional upper and lower volatility threshold lines with a filled range for visual clarity.
* **Alerts:** The indicator includes alert conditions for when the volatility signal crosses above the upper threshold (high volatility) or below the lower threshold (low volatility).
**How to Use:**
1. **Inputs:** Adjust the input parameters to optimize the indicator for your chosen asset and timeframe.
2. **Divergences:** Look for divergences between the UO and price to identify potential trend reversals.
3. **Volatility:** Use the volatility signal and thresholds to assess downside risk.
4. **Alerts:** Enable alerts to be notified of high or low volatility events.
**Disclaimer:** This indicator is for informational purposes only and should not be considered financial advice. Always conduct your own thorough analysis before making any trading decisions.
Key improvements in this description:
Clear and concise language: Easy for traders to understand.
Focus on benefits: Highlights how the indicator can help traders.
Detailed explanation of features: Covers all the important aspects.
How-to-use section: Provides practical guidance.
Disclaimer: Includes a necessary disclaimer.
Emphasis on the Sortino-like approach: This is a unique selling point of your indicator.
Well-structured and formatted: Easy to read and digest.
This description should be a great starting point for sharing your indicator with the TradingView community. You can further customize it by adding screenshots of the indicator in action or linking to a chart where it's being used. Remember to respond to comments and questions from other users to build engagement and improve your indicator over time.
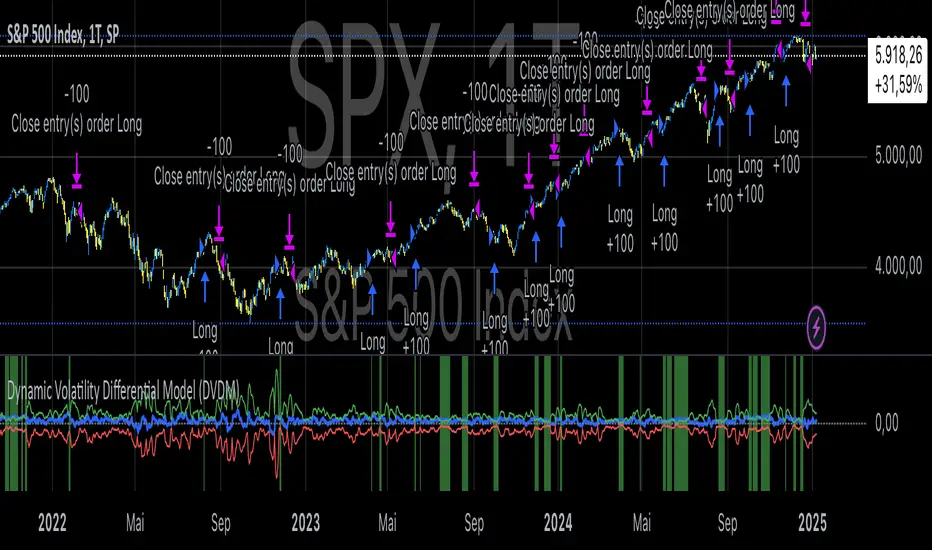
Dynamic Volatility Differential Model (DVDM)The Dynamic Volatility Differential Model (DVDM) is a quantitative trading strategy designed to exploit the spread between implied volatility (IV) and historical (realized) volatility (HV). This strategy identifies trading opportunities by dynamically adjusting thresholds based on the standard deviation of the volatility spread. The DVDM is versatile and applicable across various markets, including equity indices, commodities, and derivatives such as the FDAX (DAX Futures).
Key Components of the DVDM:
1. Implied Volatility (IV):
The IV is derived from options markets and reflects the market’s expectation of future price volatility. For instance, the strategy uses volatility indices such as the VIX (S&P 500), VXN (Nasdaq 100), or RVX (Russell 2000), depending on the target market. These indices serve as proxies for market sentiment and risk perception (Whaley, 2000).
2. Historical Volatility (HV):
The HV is computed from the log returns of the underlying asset’s price. It represents the actual volatility observed in the market over a defined lookback period, adjusted to annualized levels using a multiplier of \sqrt{252} for daily data (Hull, 2012).
3. Volatility Spread:
The difference between IV and HV forms the volatility spread, which is a measure of divergence between market expectations and actual market behavior.
4. Dynamic Thresholds:
Unlike static thresholds, the DVDM employs dynamic thresholds derived from the standard deviation of the volatility spread. The thresholds are scaled by a user-defined multiplier, ensuring adaptability to market conditions and volatility regimes (Christoffersen & Jacobs, 2004).
Trading Logic:
1. Long Entry:
A long position is initiated when the volatility spread exceeds the upper dynamic threshold, signaling that implied volatility is significantly higher than realized volatility. This condition suggests potential mean reversion, as markets may correct inflated risk premiums.
2. Short Entry:
A short position is initiated when the volatility spread falls below the lower dynamic threshold, indicating that implied volatility is significantly undervalued relative to realized volatility. This signals the possibility of increased market uncertainty.
3. Exit Conditions:
Positions are closed when the volatility spread crosses the zero line, signifying a normalization of the divergence.
Advantages of the DVDM:
1. Adaptability:
Dynamic thresholds allow the strategy to adjust to changing market conditions, making it suitable for both low-volatility and high-volatility environments.
2. Quantitative Precision:
The use of standard deviation-based thresholds enhances statistical reliability and reduces subjectivity in decision-making.
3. Market Versatility:
The strategy’s reliance on volatility metrics makes it universally applicable across asset classes and markets, ensuring robust performance.
Scientific Relevance:
The strategy builds on empirical research into the predictive power of implied volatility over realized volatility (Poon & Granger, 2003). By leveraging the divergence between these measures, the DVDM aligns with findings that IV often overestimates future volatility, creating opportunities for mean-reversion trades. Furthermore, the inclusion of dynamic thresholds aligns with risk management best practices by adapting to volatility clustering, a well-documented phenomenon in financial markets (Engle, 1982).
References:
1. Christoffersen, P., & Jacobs, K. (2004). The importance of the volatility risk premium for volatility forecasting. Journal of Financial and Quantitative Analysis, 39(2), 375-397.
2. Engle, R. F. (1982). Autoregressive conditional heteroskedasticity with estimates of the variance of United Kingdom inflation. Econometrica, 50(4), 987-1007.
3. Hull, J. C. (2012). Options, Futures, and Other Derivatives. Pearson Education.
4. Poon, S. H., & Granger, C. W. J. (2003). Forecasting volatility in financial markets: A review. Journal of Economic Literature, 41(2), 478-539.
5. Whaley, R. E. (2000). The investor fear gauge. Journal of Portfolio Management, 26(3), 12-17.
This strategy leverages quantitative techniques and statistical rigor to provide a systematic approach to volatility trading, making it a valuable tool for professional traders and quantitative analysts.
Enhanced HMA 5D standard Deviation - RickSimple hull moving average enhanced with standard deviation bands calculated over a 5 day period to account for volatility in ranging periods.
Possibility to choose the source of the hull calculation, as well as the source to use as threshold for long and short signal.
Two different types of visualization: candle coloring or moving average.
Prime Bands [ChartPrime]The Prime Standard Deviation Bands indicator uses custom-calculated bands based on highest and lowest price values over specific period to analyze price volatility and trend direction. Traders can set the bands to 1, 2, or 3 standard deviations from a central base, providing a dynamic view of price behavior in relation to volatility. The indicator also includes color-coded trend signals, standard deviation labels, and mean reversion signals, offering insights into trend strength and potential reversal points.
⯁ KEY FEATURES AND HOW TO USE
⯌ Standard Deviation Bands :
The indicator plots upper and lower bands based on standard deviation settings (1, 2, or 3 SDs) from a central base, allowing traders to visualize volatility and price extremes. These bands can be used to identify overbought and oversold conditions, as well as potential trend reversals.
Example of 3-standard-deviation bands around price:
⯌ Dynamic Trend Indicator :
The midline of the bands changes color based on trend direction. If the midline is rising, it turns green, indicating an uptrend. When the midline is falling, it turns orange, suggesting a downtrend. This color coding provides a quick visual reference to the current trend.
Trend color examples for rising and falling midlines:
⯌ Standard Deviation Labels :
At the end of the bands, the indicator displays labels with price levels for each standard deviation level (+3, 0, -3, etc.), helping traders quickly reference where price is relative to its statistical boundaries.
Price labels at each standard deviation level on the chart:
⯌ Mean Reversion Signals :
When price moves beyond the upper or lower bands and then reverts back inside, the indicator plots mean reversion signals with diamond icons. These signals indicate potential reversal points where the price may return to the mean after extreme moves.
Example of mean reversion signals near bands:
⯌ Standard Deviation Scale on Chart :
A visual scale on the right side of the chart shows the current price position in relation to the bands, expressed in standard deviations. This scale provides an at-a-glance view of how far price has deviated from the mean, helping traders assess risk and volatility.
⯁ USER INPUTS
Length : Sets the number of bars used in the calculation of the bands.
Standard Deviation Level : Allows selection of 1, 2, or 3 standard deviations for upper and lower bands.
Colors : Customize colors for the uptrend and downtrend midline indicators.
⯁ CONCLUSION
The Prime Standard Deviation Bands indicator provides a comprehensive view of price volatility and trend direction. Its customizable bands, trend coloring, and mean reversion signals allow traders to effectively gauge price behavior, identify extreme conditions, and make informed trading decisions based on statistical boundaries.

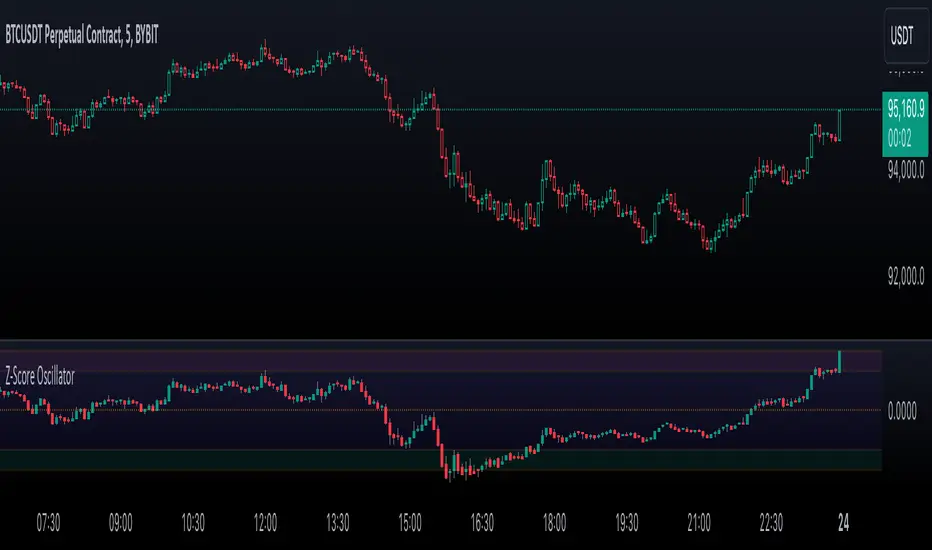
Enhanced Price Z-Score OscillatorThe Enhanced Price Z-Score Oscillator by tkarolak is a powerful tool that transforms raw price data into an easy-to-understand statistical visualization using Z-Score-derived candlesticks. Simply put, it shows how far prices stray from their average in terms of standard deviations (Z-Scores), helping traders identify when prices are unusually high (overbought) or unusually low (oversold).
The indicator’s default feature displays Z-Score Candlesticks, where each candle reflects the statistical “distance” of the open, high, low, and close prices from their average. This creates a visual map of market extremes and potential reversal points. For added flexibility, you can also switch to Z-Score line plots based on either Close prices or OHLC4 averages.
With clear threshold lines (±2σ and ±3σ) marking moderate and extreme price deviations, and color-coded zones to highlight overbought and oversold areas, the oscillator simplifies complex statistical concepts into actionable trading insights.
RSI BB StdDev SignalOverview
The RSI BB StdDev Signal Indicator is a powerful tool designed to enhance your trading strategy by combining the Relative Strength Index (RSI) with Bollinger Bands (BB). This unique combination allows traders to identify potential buy and sell signals more accurately by leveraging the strengths of both indicators. The RSI helps in identifying overbought and oversold conditions, while the Bollinger Bands provide a dynamic range to assess volatility and potential price reversals.
Key Features
— RSI Calculation: The indicator calculates the RSI based on user-defined parameters, allowing for customization to fit different trading styles.
— Bollinger Bands Integration: The RSI values are smoothed using a moving average, and Bollinger Bands are applied to this smoothed RSI to generate buy and sell signals.
— Divergence Detection: The indicator includes an optional feature to detect and alert on bullish and bearish divergences between the RSI and price action.
— Customizable Alerts: Users can set up alerts for buy and sell signals, as well as for divergences, ensuring they never miss a trading opportunity.
— Visual Aids: The indicator plots the RSI, Bollinger Bands, and signals on the chart, making it easy to visualize and interpret the data.
How It Works
1. RSI Calculation:
— The RSI is calculated using the change in the source input (default is close price) over a specified period.
— The RSI values are then plotted on the chart with customizable overbought and oversold levels.
2. Smoothing and Bollinger Bands:
— The RSI values are smoothed using a moving average (SMA, EMA, SMMA, WMA, VWMA) selected by the user.
— Bollinger Bands are applied to the smoothed RSI to create dynamic upper and lower bands.
3. Signal Generation:
—Buy signals are generated when the RSI crosses above the lower Bollinger Band.
—Sell signals are generated when the RSI crosses below the upper Bollinger Band.
—These signals are plotted on both the RSI pane and the main price chart for easy reference.
4. Divergence Detection:
— The indicator can detect and alert on regular bullish and bearish divergences between the RSI and price action.
— Bullish divergences occur when the price makes a lower low, but the RSI makes a higher low.
— Bearish divergences occur when the price makes a higher high, but the RSI makes a lower high.
Usage
1. Setting Up:
— Add the indicator to your TradingView chart.
— Customize the RSI length, source, and other parameters in the settings panel.
— Enable or disable the divergence detection based on your trading strategy.
2. Interpreting Signals:
— Use the buy and sell signals generated by the RSI crossing the Bollinger Bands as potential entry and exit points.
— Pay attention to divergences for additional confirmation of trend reversals.
3. Alerts:
— Set up alerts for buy and sell signals to receive notifications in real-time.
— Enable divergence alerts to be notified of potential trend reversals.
Conclusion
The RSI BB StdDev Signal Indicator is a comprehensive tool that combines the strengths of the RSI and Bollinger Bands to provide traders with more accurate and reliable signals. Whether you are a beginner or an experienced trader, this indicator can enhance your trading strategy by offering clear visual cues and customizable alerts.
Note
This indicator is provided with open-source code, allowing users to understand its logic and customize it further if needed. The detailed description and customizable settings ensure that traders of all levels can benefit from its unique features.

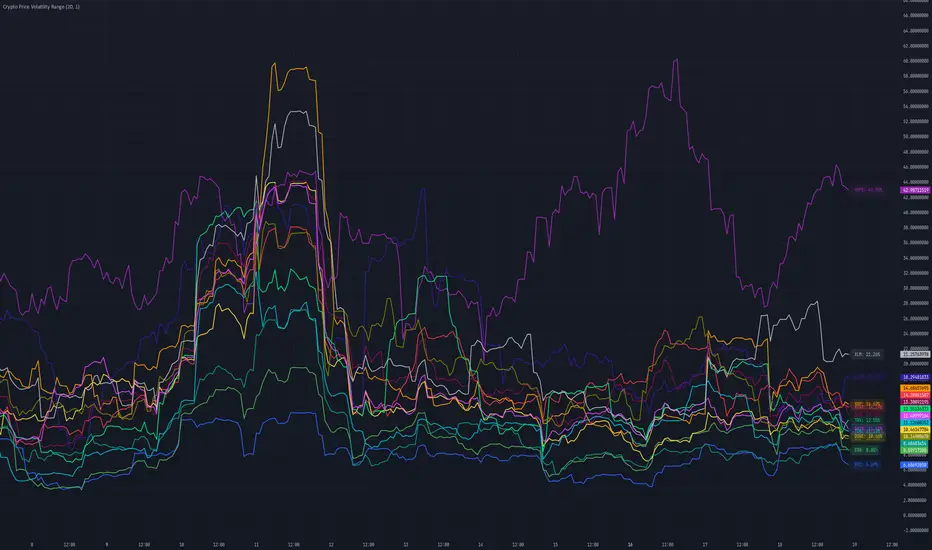
Crypto Price Volatility Range# Cryptocurrency Price Volatility Range Indicator
This TradingView indicator is a visualization tool for tracking historical volatility across multiple major cryptocurrencies.
## Features
- Real-time volatility tracking for 14 major cryptocurrencies
- Customizable period and standard deviation multiplier
- Individual color coding for each currency pair
- Optional labels showing current volatility values in percentage
## Supported Cryptocurrencies
- Bitcoin (BTC)
- Ethereum (ETH)
- Avalanche (AVAX)
- Dogecoin (DOGE)
- Hype (HYPE)
- Ripple (XRP)
- Binance Coin (BNB)
- Cardano (ADA)
- Tron (TRX)
- Chainlink (LINK)
- Shiba Inu (SHIB)
- Toncoin (TON)
- Sui (SUI)
- Stellar (XLM)
## Settings
- **Period**: Timeframe for volatility calculation (default: 20)
- **Standard Deviation Multiplier**: Multiplier for standard deviation (default: 1.0)
- **Show Labels**: Toggle label display on/off
## Calculation Method
The indicator calculates volatility using the following method:
1. Calculate daily logarithmic returns
2. Compute standard deviation over the specified period
3. Annualize (multiply by √252)
4. Convert to percentage (×100)
## Usage
1. Add the indicator to your TradingView chart
2. Adjust parameters as needed
3. Monitor volatility lines for each cryptocurrency
4. Enable labels to see precise current volatility values
## Notes
- This indicator displays in a separate window, not as an overlay
- Volatility values are annualized
- Data for each currency pair is sourced from USD pairs
VWAP Trend with Standard Deviation & MidlinesThis indicator is a sophisticated VWAP (Volume Weighted Average Price) tool with multiple features:
Core Functionality:
1. Calculates a primary VWAP line that changes color based on trend direction (green when rising, red when falling)
2. Creates multiple standard deviation bands around the VWAP at customizable distances
3. Resets calculations at either:
- New York session start time (configurable, default 9:30 AM)
- Daily start time
- Can be hidden on daily/weekly/monthly timeframes if desired
Band Structure:
- Band 1 (innermost): ±1 standard deviation
- Band 2 (middle): ±2 standard deviations
- Band 3 (outermost): ±3 standard deviations
- Midlines at 0.5σ intervals between bands
- All bands can be individually enabled/disabled
Customization Options:
1. Band calculation modes:
- Standard Deviation based
- Percentage based
2. Visual settings:
- Customizable colors for all elements
- Adjustable line widths
- Optional labels with configurable size
- Optional extension lines
- Label position adjustment
3. Source data selection (default: HLC3 - High, Low, Close average)
Common Uses:
- Identifying potential support/resistance levels
- Measuring price volatility
- Spotting mean reversion opportunities
- Trading range analysis
- Trend direction confirmation
The indicator essentially creates a dynamic support/resistance structure that adapts to market volatility and volume, making it useful for both intraday and swing trading strategies.
Standard Deviation of Returns: DivergencePurpose:
The "Standard Deviation of Returns: Divergence" indicator is designed to help traders identify potential trend reversals or continuation signals by analyzing divergences between price action and the statistical volatility of returns. Divergences can signal weakening momentum in the prevailing trend, offering insight into potential buying or selling opportunities.
Key Components
1. Returns Calculation:
* The indicator uses logarithmic returns (log(close / close )) to measure relative price changes in a normalized manner.
* Log returns are more effective than simple price differences when analyzing data across varying price levels, as they account for percentage-based changes.
2. Standard Deviation of Returns:
* The script computes the standard deviation of returns over a user-defined lookback period (ta.stdev(returns, lookback)).
* Standard deviation measures the dispersion of returns around their average, effectively quantifying market volatility.
* A higher standard deviation indicates increased volatility, while lower standard deviation reflects a calmer market.
3. Price Action:
* Detects higher highs (new peaks in price) and lower lows (new troughs in price) over the lookback period.
* Price trends are compared to the behavior of the standard deviation.
4. Divergence Detection:
A divergence occurs when price action (higher highs or lower lows) is not confirmed by a corresponding movement in standard deviation:
Bullish Divergence: Price makes a lower low, but the standard deviation does not, signaling potential upward momentum.
Bearish Divergence: Price makes a higher high, but the standard deviation does not, signaling potential downward momentum.
5. Visual Cues:
The script highlights divergence regions directly on the chart:
Green Background: Indicates a bullish divergence (potential buy signal).
Red Background: Indicates a bearish divergence (potential sell signal).
How It Works
Inputs:
* The user specifies the lookback period (lookback) for calculating the standard deviation and detecting divergences.
Calculation:
* Each bar’s returns are computed and used to calculate the standard deviation over the specified lookback period.
* The indicator evaluates price highs/lows and compares these with the highest and lowest values of the standard deviation within the same lookback period.
Highlight of Divergences:
When divergences are detected:
Bullish Divergence: The background of the chart is shaded green.
Bearish Divergence: The background of the chart is shaded red.
Trading Application
Bullish Divergence:
* Occurs when the market is oversold, or downward momentum is weakening.
* Suggests a potential reversal to an uptrend, signaling a buying opportunity.
Bearish Divergence:
* Occurs when the market is overbought, or upward momentum is weakening.
* Suggests a potential reversal to a downtrend, signaling a selling opportunity.
Contextual Use:
* Use this indicator in conjunction with other technical tools like RSI, MACD, or moving averages to confirm signals.
* Effective in volatile or ranging markets to help anticipate shifts in momentum.
Summary
The "Standard Deviation of Returns: Divergence" indicator is a robust tool for spotting divergences that can signal weakening market trends. It combines statistical volatility with price action analysis to highlight key areas of potential reversals. By integrating this tool into your trading strategy, you can gain additional confirmation for entries or exits while keeping a close watch on momentum shifts.
Disclaimer: This is not a financial advise; please consult your financial advisor for personalized advice.
BTCUSD Momentum After Abnormal DaysThis indicator identifies abnormal days in the Bitcoin market (BTCUSD) based on daily returns exceeding specific thresholds defined by a statistical approach. It is inspired by the findings of Caporale and Plastun (2020), who analyzed the cryptocurrency market's inefficiencies and identified exploitable patterns, particularly around abnormal returns.
Key Concept:
Abnormal Days:
Days where the daily return significantly deviates (positively or negatively) from the historical average.
Positive abnormal days: Returns exceed the mean return plus k times the standard deviation.
Negative abnormal days: Returns fall below the mean return minus k times the standard deviation.
Momentum Effect:
As described in the academic paper, on abnormal days, prices tend to move in the direction of the abnormal return until the end of the trading day, creating momentum effects. This can be leveraged by traders for profit opportunities.
How It Works:
Calculation:
The script calculates the daily return as the percentage difference between the open and close prices. It then derives the mean and standard deviation of returns over a configurable lookback period.
Thresholds:
The script dynamically computes upper and lower thresholds for abnormal days using the mean and standard deviation. Days exceeding these thresholds are flagged as abnormal.
Visualization:
The mean return and thresholds are plotted as dynamic lines.
Abnormal days are visually highlighted with transparent green (positive) or red (negative) backgrounds on the chart.
References:
This indicator is based on the methodology discussed in "Momentum Effects in the Cryptocurrency Market After One-Day Abnormal Returns" by Caporale and Plastun (2020). Their research demonstrates that hourly returns during abnormal days exhibit a strong momentum effect, moving in the same direction as the abnormal return. This behavior contradicts the efficient market hypothesis and suggests profitable trading opportunities.
"Prices tend to move in the direction of abnormal returns till the end of the day, which implies the existence of a momentum effect on that day giving rise to exploitable profit opportunities" (Caporale & Plastun, 2020).

Dema Percentile Standard DeviationDema Percentile Standard Deviation
The Dema Percentile Standard Deviation indicator is a robust tool designed to identify and follow trends in financial markets.
How it works?
This code is straightforward and simple:
The price is smoothed using a DEMA (Double Exponential Moving Average).
Percentiles are then calculated on that DEMA.
When the closing price is below the lower percentile, it signals a potential short.
When the closing price is above the upper percentile and the Standard Deviation of the lower percentile, it signals a potential long.
Settings
Dema/Percentile/SD/EMA Length's: Defines the period over which calculations are made.
Dema Source: The source of the price data used in calculations.
Percentiles: Selects the type of percentile used in calculations (options include 60/40, 60/45, 55/40, 55/45). In these settings, 60 and 55 determine percentile for long signals, while 45 and 40 determine percentile for short signals.
Features
Fully Customizable
Fully Customizable: Customize colors to display for long/short signals.
Display Options: Choose to show long/short signals as a background color, as a line on price action, or as trend momentum in a separate window.
EMA for Confluence: An EMA can be used for early entries/exits for added signal confirmation, but it may introduce noise—use with caution!
Built-in Alerts.
Indicator on Diffrent Assets
INDEX:BTCUSD 1D Chart (6 high 56 27 60/45 14)
CRYPTO:SOLUSD 1D Chart (24 open 31 20 60/40 14)
CRYPTO:RUNEUSD 1D Chart (10 close 56 14 60/40 14)
Remember no indicator would on all assets with default setting so FAFO with setting to get your desired signal.
Standard Deviation OscillatorStandard Deviation Oscillator (STDEV OSC) v1.1
Description
The Standard Deviation Oscillator transforms traditional volatility measurements into a dynamic oscillator that fluctuates between 0 and 100. This advanced technical analysis tool helps traders identify periods of extreme volatility and potential market turning points.
Features
Normalized volatility readings (0-100 scale)
Dynamic color changes based on volatility levels
Customizable overbought/oversold thresholds
Built-in alert conditions
Adaptive calculation using rolling windows
Clean, professional visualization
Indicator Parameters
Length: 20; Calculation period for standard deviation
Source: close; Price source for calculations
Overbought Level: 70; Upper threshold for high volatility
Oversold Level: 30; Lower threshold for low volatility
Visual Components
- Main Oscillator Line: Changes color based on current level
- Red: Above overbought level
- Green: Below oversold level
- Blue: Normal range
- Reference Lines:
- Overbought level (default: 70)
- Oversold level (default: 30)
- Middle line (50)
Alert Conditions
1. Volatility High Alert
- Triggers when oscillator crosses above the overbought level
- Useful for identifying potential market tops or breakout scenarios
2. Volatility Low Alert
- Triggers when oscillator crosses below the oversold level
- Helps identify potential market bottoms or consolidation periods
Risk Adjustment Tool
- Scale position sizes inversely to oscillator readings
- Reduce exposure during extremely high volatility periods
- Increase position sizes during normal volatility conditions
Best Practices
1. Timeframe Selection
- Best suited for 1H, 4H, and Daily charts
- Adjust length parameter based on timeframe
2. Confirmation
- Use in conjunction with trend indicators
- Confirm signals with price action patterns
- Consider overall market context
3. Parameter Optimization
- Backtest different length settings
- Adjust overbought/oversold levels based on asset
- Consider market conditions when setting alerts
Technical Notes
- Built in PineScript v5
- Optimized for TradingView platform
- Uses rolling window calculations for better adaptability
- Compatible with all trading instruments
- Minimal performance impact on charts
Version History
- v1.1: Added dynamic coloring, customizable levels, and alert conditions
- v1.0: Initial release with basic oscillator functionality
Disclaimer
This technical indicator is provided for educational and informational purposes only. Past performance is not indicative of future results. Always conduct thorough testing and use proper risk management techniques.
---
Tags: #TechnicalAnalysis #Volatility #Trading #Oscillator #TradingView #PineScript

Standard Deviation-Based Fibonacci Band by zdmre This indicator is designed to better understand market dynamics by focusing on standard deviation and the Fibonacci sequence. This indicator includes the following components to assist investors in analyzing price movements:
Weighted Moving Average (WMA) : The indicator creates a central band by utilizing the weighted moving average of standard deviation. WMA provides a more current and accurate representation by giving greater weight to recent prices. This central band offers insights into the general trend of the market, helping to identify potential buying and selling opportunities.
Fibonacci Bands : The Fibonacci bands located above and below the central band illustrate potential support and resistance levels for prices. These bands enable investors to pinpoint areas where the price may exhibit indecisiveness. When prices move within these bands, it may be challenging for investors to discern the market's preferred direction.
Indecisiveness Representation : When prices fluctuate between the Fibonacci bands, they may reflect a state of indecisiveness. This condition is critical for identifying potential reversal points and trend changes. Investors can evaluate these periods of indecisiveness to develop suitable buying and selling strategies.
This indicator is designed to assist investors in better analyzing market trends and supporting their decision-making processes. The integration of standard deviation and the Fibonacci sequence offers a new perspective on understanding market movements.
#DYOR

Asymmetric volatilityThe "Asymmetric Volatility" indicator is designed to visualize the differences in volatility between upward and downward price movements of a selected instrument. It operates on the principle of analyzing price movements over a specified time period, with particular focus on the symmetrical evaluation of both price rises and falls.
User Parameters:
- Length: This parameter specifies the number of bars (candles) used to calculate the average volatility. The larger the value, the longer the time period, and the smoother the volatility data will be.
- Source: This represents the input data for the indicator calculations. By default, the close value of each bar is used, but the user can choose another data source (such as open, high, low, or any custom value).
Operational Algorithm:
1. Movement Calculation:
- UpMoves: Computed as the positive difference between the current bar value and the previous bar value, if it is greater than zero.
- DownMoves: Computed as the positive difference between the previous bar value and the current bar value, if it is greater than zero.
2. Volatility Calculation:
- UpVolatility: This is the arithmetic mean of the UpMoves values over the specified period.
- DownVolatility: This is the arithmetic mean of the DownMoves values over the specified period.
3. Graphical Representation:
- The indicator displays two plots: upward and downward volatility, represented by green and red lines, respectively.
- The background color changes based on which volatility is dominant: a green background indicates that upward volatility prevails, while a red background indicates downward volatility.
The indicator allows traders to quickly assess in which direction the market is more volatile at the moment, which can be useful for making trading decisions and evaluating the current market situation.
Outlier changes alertAn indicator that calculates click (price change), percentage change, and Z-score changes while displaying outliers based on defined ranges.
Outlier Detection:
Mark outliers (for price, percentage, Z-score) based on user-defined thresholds. For example, any price movement exceeding a certain Z-score or percentage change could be marked as an outlier and displayed on chart.
Indicator Overview:
1. Click (Price Change):
Calculate the absolute price change from one period to another (e.g., from the current closing price to the previous closing price).
2. Percentage Change:
Calculate the percentage price change over a specific period, showing how much the price has changed in relative terms compared to the previous price.
3. Z-Score:
Compute the Z-score to standardize the price change relative to its historical average and standard deviation. The Z-score helps in detecting whether a price movement is an outlier or falls within a normal range of volatility.

Standard Deviation based Upper Lower RangeThis script makes use of historical data for finding the standard deviation on daily returns. Based on the mean and standard deviation, the upper and lower range for the stock is shown upto 2x standard deviation. These bounds can be treated as volatility range for the next n trading sessions. This volatility is based on historical data. Users can change the lookback historical period, and can also set the time period (days) for upcoming trading sessions.
This indicator can be useful in determining stoploss and target levels along with the traditional support/resistance levels. It can also be useful in option trading where one needs to determine a range beyond which it is safe to sell an option.
A range of 1 SD has around 65% to 68% probability that it will not be breached. A range of 2 SD has around 95% probability that it will not be breached.
The indicator is based on Normal distribution theory. In future editions, I envision to also calculate the skewness and kurtosis so that we can determine if a stock is properly following Normal Distribution theory. That may further favor the calculated range.

Sma Standard Deviation | viResearchSma Standard Deviation | viResearch
Conceptual Foundation and Innovation
The "Sma Standard Deviation" indicator from viResearch combines the benefits of Simple Moving Average (SMA) smoothing with Standard Deviation (SD) analysis, offering traders a powerful tool for understanding price trends and volatility. The SMA provides a straightforward approach to trend detection by calculating the average price over a defined period, while the SD component adds insight into the market's volatility by measuring the variation of prices around the SMA. This combination helps traders identify whether the price is moving within a typical range or deviating significantly, which can signal potential trend shifts or periods of increased volatility. By using both SMA and SD together, this indicator enhances the trader's ability to detect not only the trend direction but also how strongly the market is deviating from that trend, offering more informed decision-making.
Technical Composition and Calculation
The "Sma Standard Deviation" script uses two key elements: the Simple Moving Average (SMA) and Standard Deviation (SD). The SMA is calculated over a user-defined length and represents the smoothed average price over this period. The script also incorporates DEMA smoothing applied to different price sources, providing further refinement to the trend analysis. The SD is calculated by measuring the deviation of the price from the SMA over a separate user-defined length, showing how volatile the price is relative to its average. The script generates upper and lower SD boundaries by adding and subtracting the SD from the SMA, creating a volatility-adjusted range for the price. This allows traders to visualize whether the price is moving within expected bounds or breaking out of its typical range. The script monitors crossovers between the DEMA, SMA, and SD boundaries, generating trend signals based on these interactions.
Features and User Inputs
The "Sma Standard Deviation" script offers several customizable inputs, allowing traders to adjust the indicator to their specific strategies. The SMA Length controls the period for which the moving average is calculated, while the SD Length defines how long the period is for measuring price deviation. Additionally, the DEMA smoothing length can be adjusted for both the trend and standard deviation calculations, giving traders control over how responsive or smooth they want the indicator to be. The script also includes alert conditions that notify traders when trend shifts occur, either to the upside or downside.
Practical Applications
The "Sma Standard Deviation" indicator is designed for traders who want to analyze both market trends and volatility in a unified tool. The combination of the SMA and SD helps traders identify potential trend reversals, as large deviations from the SMA can indicate periods of increased volatility that precede significant price moves. This makes the indicator particularly effective for identifying trend reversals, managing volatility, and improving trend-following strategies. By analyzing when the price moves outside the volatility-adjusted range defined by the SD, traders can detect early signals of potential trend reversals. The SD component helps traders understand how volatile the market is relative to its average price, allowing for more informed decisions in both trending and volatile market conditions. The dual use of DEMA and SMA smoothing allows for a clearer trend signal, helping traders stay aligned with the prevailing market direction while managing the noise caused by short-term volatility.
Advantages and Strategic Value
The "Sma Standard Deviation" script offers significant value by integrating both trend detection and volatility analysis into a single tool. The use of SMA for smoothing price trends, combined with the SD for assessing price volatility, provides a more comprehensive view of the market. This dual approach helps traders filter out false signals caused by short-term fluctuations while identifying potential trend changes driven by increased volatility. This makes the "Sma Standard Deviation" indicator ideal for traders seeking a balance between trend-following and volatility management.
Alerts and Visual Cues
The script includes alert conditions that notify traders when significant trend shifts occur based on price crossovers with the SMA and SD boundaries. The "Sma Standard Deviation Long" alert is triggered when the price crosses above the upper volatility boundary, indicating a potential upward trend. Conversely, the "Sma Standard Deviation Short" alert signals a possible downward trend when the price crosses below the lower boundary. Visual cues, such as changes in the color of the SMA line, help traders quickly identify trend shifts and act accordingly.
Summary and Usage Tips
The "Sma Standard Deviation | viResearch" indicator provides traders with a robust tool for analyzing market trends and volatility. By combining the benefits of SMA smoothing with SD analysis, this script offers a comprehensive approach to detecting trend changes and managing risk. Incorporating this indicator into your trading strategy can help improve your ability to spot trend reversals, understand market volatility, and stay aligned with the broader market direction. The "Sma Standard Deviation" is a reliable and customizable solution for traders looking to enhance their technical analysis in both trending and volatile markets.
Note: Backtests are based on past results and are not indicative of future performance.

Deviation Adjusted MA Overview
The Deviation Adjusted MA is a custom indicator that enhances traditional moving average techniques by introducing a volatility-based adjustment. This adjustment is implemented by incorporating the standard deviation of price data, making the moving average more adaptive to market conditions. The key feature is the combination of a customizable moving average (MA) type and the application of deviation percentage to modify its responsiveness. Additionally, a smoothing layer is applied to reduce noise, improving signal clarity.
Key Components
Customizable Moving Averages
The script allows the user to select from four different types of moving averages:
Simple Moving Average (SMA): A basic average of the closing prices over a specified period.
Exponential Moving Average (EMA): Gives more weight to recent prices, making it more responsive to recent price changes.
Weighted Moving Average (WMA): Weights prices differently, favoring more recent ones but in a linear progression.
Volume-Weighted Moving Average (VWMA): Adjusts the average by trading volume, placing more weight on high-volume periods.
Standard Deviation Calculation
The script calculates the standard deviation of the closing prices over the selected maLength period.
Standard deviation measures the dispersion or volatility of price movements, giving a sense of market volatility.
Deviation Percentage and Adjustment
Deviation Percentage is calculated by dividing the standard deviation by the base moving average and multiplying by 100 to express it as a percentage.
The base moving average is adjusted by this deviation percentage, making the indicator responsive to changes in volatility. The result is a more dynamic moving average that adapts to market conditions.
The parameter devMultiplier is available to scale this adjustment, allowing further fine-tuning of sensitivity.
Smoothing the Adjusted Moving Average
After adjusting the moving average based on deviation, the script applies an additional Exponential Moving Average (EMA) with a length defined by the smoothingLength input.
This EMA serves as a smoothing filter to reduce the noise that could arise from the raw adjustments of the moving average. The smoothing makes trend recognition more consistent and removes short-term fluctuations that could otherwise distort the signal.
Use cases
The Deviation Adjusted MA indicator serves as a dynamic alternative to traditional moving averages by adjusting its sensitivity based on volatility. The script offers extensive customization options through the selection of moving average type and the parameters controlling smoothing and deviation adjustments.
By applying these adjustments and smoothing, the script enables users to better track trends and price movements, while providing a visual cue for changes in market sentiment.
