EMA Separation (LFZ Scalps) v6 — Early TriggerPlots the percentage distance between a fast and a slow EMA (default 9 & 21) to gauge trend strength and filter out choppy London Flow Zone breakouts.
• Gray – EMAs nearly flat (low momentum, avoid trades)
• Orange – early trend building
• Green/Red – strong directional momentum
Useful for day-traders: wait for the gap to widen beyond your chosen threshold (e.g., 0.25 %) before entering a breakout. Adjustable EMA lengths and alert when the separation exceeds your “strong trend” level.
Regressions

Nadaraya-Watson Multi-TF DashboardThis script is a Multi-Timeframe Flip State Dashboard based on Nadaraya-Watson: Rational Quadratic Kernel (Non-Repainting) indicator. It visualizes trend "flip" states across up to 8 custom timeframes using a consistent, non-repainting methodology. Built on 1-minute data, each timeframe row in the table updates only after its bar fully closes, ensuring accuracy and eliminating repainting issues.
Key features:
✅ Based on the Nadaraya-Watson Rational Quadratic Kernel, used to estimate trend direction
🧠 Each timeframe uses the same base 1-minute data for consistency across resolutions
🔄 Flip state detection is defined by slope reversals in the kernel regression
🧱 Fully supports non-repainting, close-confirmed states using lookahead=off
🧮 Configurable lookback window, kernel weighting, lag, and timeframes
🎨 Visual dashboard plots each TF’s state as a colored cell (green for bullish, red for bearish)
🛠️ Includes inline plots and debug traces to help visualize regression and flip logic
This dashboard is ideal for traders who want a compact visual overview of confirmed trend shifts across multiple timeframes, all using a mathematically grounded, TF-consistent model.

Alerta de toque de la 200-Week SMACuando el precio toca la MMS de 200 semanas es una posible compra.

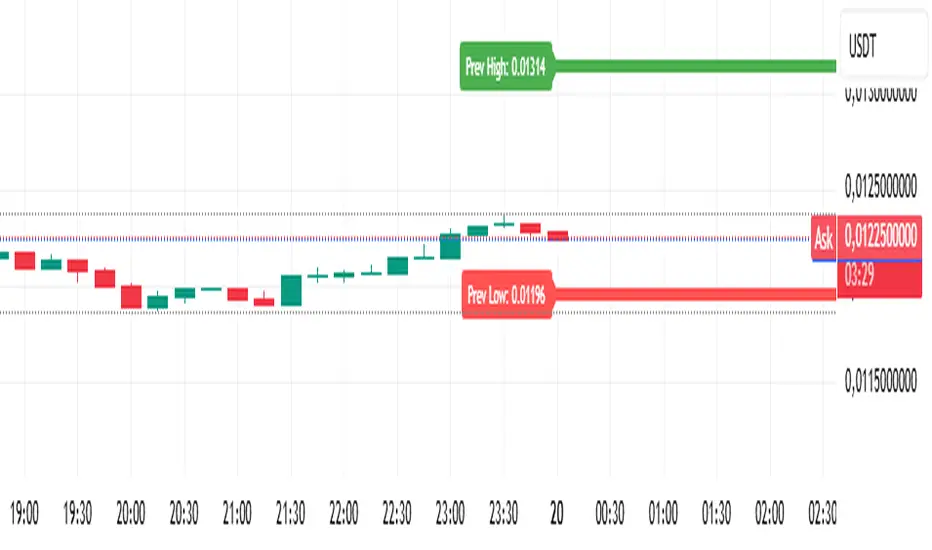
Analitica Trading — Previous Day SR (2 lines + labels) 2.0📊 Analitica Trading — Previous Day SR (Support & Resistance)
This indicator displays the previous day’s key levels on any timeframe:
Prev High → Green horizontal line with label.
Prev Low → Red horizontal line with label.
🔹 Stable across timeframes: The levels are calculated from the daily candles and remain fixed, no matter if you switch to 1D, 1H, or 5m.
🔹 Simple & clean: Exactly two lines only (no duplicates).
🔹 Price labels included: Each line has a clear tag showing the exact level.
🔹 Dynamic update: Lines refresh automatically at the start of each new daily session.
🔹 Alerts: Optional alerts trigger when the price breaks above the Prev High or below the Prev Low.
💡 Ideal for support/resistance trading, breakouts, and Smart Money Concepts (SMC) strategies.
Omega ATR Indicator📖 Introduction
The Ω ATR Indicator was created to provide a more complete and professional framework for volatility analysis than the classic Average True Range (ATR).
While the traditional ATR is a useful tool, it has limitations: it delivers a simple rolling average of volatility, but it does not adapt to market regimes, it does not highlight extreme events, and it often leaves the trader with incomplete information about risk.
The Ω ATR takes the same foundation and elevates it into a multi-dimensional volatility dashboard, adding statistical layers, adaptive calculations, and clear visual references that allow traders to interpret volatility in a way that is immediately actionable.
🔎 What makes it different from a standard ATR?
This indicator introduces several features beyond the classic formula:
True Range Core – plots the raw True Range (TR) for each bar, providing a direct, bar-by-bar view of volatility impulses.
Standard & Adjusted ATR – includes both the conventional ATR (smoothed average) and an Adjusted ATR that automatically corrects for extreme conditions by incorporating percentile rescaling.
Percentile Volatility Levels – dynamically calculated extreme thresholds (99.8%, 75%, 50%, 25%), plotted as dotted levels across the chart. These act as reference lines for “normal” vs. “abnormal” volatility, useful for spotting unusual price expansions or contractions.
Linear Regression Volatility Trend – overlays a regression line of volatility, showing whether the market is moving toward expansion (rising vol), contraction (falling vol), or stability.
Monetary Value Translation – the indicator converts volatility into points, ticks, and dollar values (based on the instrument’s point value). This allows futures traders and high-value instruments users to immediately see how much volatility is “worth” in cash terms.
Interactive Table Display – a real-time statistics table is displayed directly on the chart, showing:
SMA of ATR in $ and points
Percentile-based volatility range (VAR) in $ and points
Tick equivalences, for quick position sizing
⚡ How traders can use it
The Ω ATR Indicator is designed to be versatile, fitting both discretionary traders and systematic strategy developers.
Risk Management: ATR-based stop losses and position sizing are significantly improved by using the adjusted ATR and percentile thresholds. Traders can size their positions according to volatility regimes, not just raw averages.
Breakout & Exhaustion Detection: When TR or ATR values spike above the 99.8% or 95% percentile levels, this often corresponds to breakout conditions or volatility exhaustion — useful for breakout strategies, mean-reversion setups, and volatility fades.
Market Regime Identification: The regression line helps distinguish if volatility is rising (trending environment, larger swings expected) or compressing (range-bound environment, lower risk opportunities).
Multi-Asset Flexibility: Works equally well on equities, futures, crypto, and FX. Its point/tick/dollar conversion makes it especially powerful for futures traders who need to quantify risk precisely.
Scalping to Swing Trading: On lower timeframes, it acts as a micro-volatility detector; on higher timeframes, it functions as a strategic risk gauge for position management.
⚙️ Settings and Customization
Length: The ATR lookback period (default = 34).
Shorter lengths (14–21) for intraday traders who want fast response.
Longer lengths (34–55) for swing/position traders who want smoother readings.
AVG / ADJ AVG: Toggle to display the standard ATR or the adjusted ATR.
Volatility Levels: Enable/disable up to 4 percentile-based levels (1st = 25%, 2nd = 50%, 3rd = 75%, 4th = 99.8%). Recommended: keep 3 levels active for clarity.
Color Controls: All plots and levels are fully customizable to match your chart style.
Table Display: Positioned on the chart (default: middle-right) with key values updated in real time.
🧭 Best Practices for Use
Combine with Trend Tools: Volatility readings are most powerful when combined with trend filters or volume analysis. For example, a breakout with both high volatility and trend confirmation is stronger than either alone.
ATR Stops: Use the Adjusted ATR rather than the standard one when trailing stops in highly volatile instruments like crypto or Nasdaq futures, as it adapts to outlier spikes.
Dollar Risk Translation: Use the dollar-value outputs to predefine maximum acceptable risk per trade (e.g., “I only risk $250 per position”). This bridges volatility to portfolio risk management.
Event Monitoring: Around economic events or earnings, expect volatility spikes above higher percentile levels. The indicator makes these moves instantly visible.
📌 Summary
The Ω ATR Indicator is not just “another ATR.” It is a comprehensive volatility framework that transforms volatility from a simple statistic into an actionable trading signal.
By combining:
the classic ATR,
an adjusted ATR,
percentile extremes,
regression-based volatility trends,
and real-time dollar conversions,
…this tool allows traders to precisely understand, visualize, and act on volatility in ways that a standard ATR simply cannot provide.
Whether you are scalping intraday moves, swing trading equities, or managing futures positions, the Ω ATR equips you with a professional-grade volatility dashboard that clarifies risk, highlights opportunity, and adapts across all markets and timeframes.
👉 Designed and developed by OmegaTools for traders who demand precision, clarity, and adaptability in their volatility analysis.

BTCUSD Dual Thrust (1H)BTCUSD Dual Thrust (1H) — Indicator
Overview
The Dual Thrust is a classic breakout-type strategy designed to capture strong directional moves when markets show imbalance between buyers and sellers. This indicator adapts the method specifically for BTCUSD on the 1-Hour timeframe, showing dynamic Buy/Sell trigger levels and live signals.
Origin
The Dual Thrust system was originally introduced by Michael Vitucci and has been widely used in futures and high-volatility markets. It was designed as a day-trading breakout framework, where daily high/low and close data define the range for the next session’s trade triggers.
How it Works
Each new day, the indicator calculates a “breakout range” using daily price data.
Two trigger levels are projected from the daily open:
Buy Trigger: Open + Range × KUp
Sell Trigger: Open - Range × KDn
Range can be built from either:
Classic Dual Thrust formula: max(High - Close , Close - Low) over a lookback period, or
ATR-based range: for volatility-adaptive signals.
A LONG signal fires when price crosses above the Buy Trigger.
An EXIT signal fires when price crosses below the Sell Trigger.
Buy/Sell lines step forward across each intraday bar until recalculated at the next daily open.
Practical Use
Optimized for BTCUSD 1-Hour charts (crypto’s volatility provides stronger follow-through).
Use the Buy/Sell levels as dynamic breakout lines or as confluence with your own setups.
Alerts are built in, so you can receive notifications when a LONG or EXIT condition triggers.
Designed as an indicator only (not a backtest strategy).
Key Features
✅ Daily Buy/Sell trigger lines auto-calculated and forward-filled
✅ LONG / EXIT labels on signals
✅ Optional ATR mode for volatility regimes
✅ Optional bar coloring for easy visual scanning
✅ Alerts ready for live monitoring
⚡️ Tip: While this indicator highlights breakout opportunities, effectiveness can improve when combined with trend filters (e.g., 200-SMA) or when aligned with higher timeframe supply/demand zones.

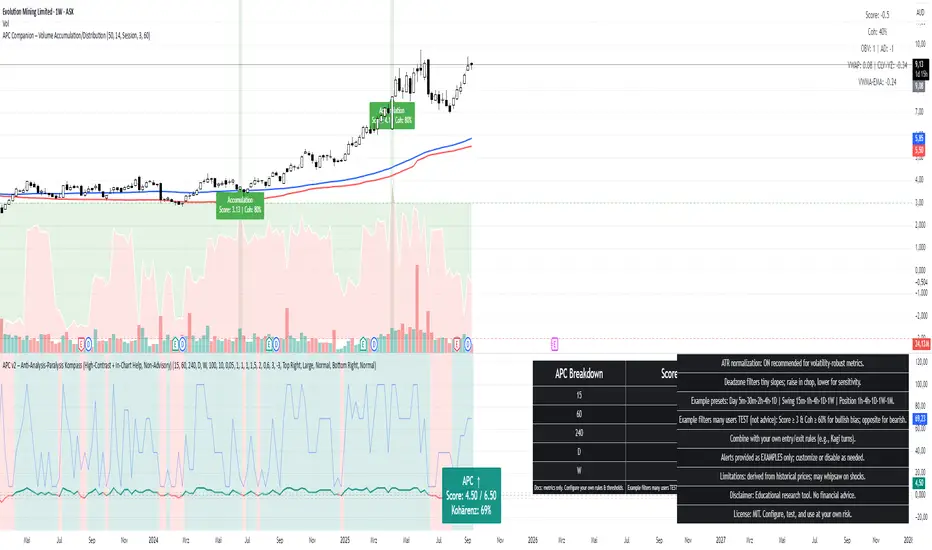
APC Companion – Volume Accumulation/DistributionIndicator Description (TradingView – Open Source)
APC Companion – Volume Accumulation/Distribution Filter
(Designed to work standalone or together with the APC Compass)
What this indicator does
The APC Companion measures whether markets are under Accumulation (buying pressure) or Distribution (selling pressure) by combining:
Chaikin A/D slope – volume flow into price moves
On-Balance Volume momentum – confirms trend strength
VWAP spread – price vs. fair value by traded volume
CLV × Volume Z-Score – detects intrabar absorption / selling pressure
VWMA vs. EMA100 – confirms whether weighted volume supports price action
The result is a single Acc/Dist Score (−5 … +5) and a Coherence % showing how many signals agree.
How to interpret
Score ≥ +3 & Coherence ≥ 60% → Accumulation (green) → market supported by buyers
Score ≤ −3 & Coherence ≥ 60% → Distribution (red) → market pressured by sellers
Anything in between = neutral (no strong bias)
Using with APC Compass
Long trades: Only take Compass Long signals when Companion shows Accumulation.
Short trades: Only take Compass Short signals when Companion shows Distribution.
Neutral Companion: Skip or reduce size if there is no confirmation.
This filter greatly reduces false signals and improves trade quality.
Best practice
Swing trading: 4H / 1D charts, lenZ 40–80, lenSlope 14–20
Intraday: 5m–30m charts, lenZ 20–30, lenSlope 10–14
Position sizing: Increase with higher Coherence %, reduce when below 60%
Exits: Reduce or close if Score drops back to neutral or flips opposite
Disclaimer
This script is published open source for educational purposes only.
It is not financial advice. Test thoroughly before using in live trading.
Weekly Fibonacci Pivot Levelsthis indicator in simple ways, draw the weekly fibo zones based on calculations
weekly zones are drawn automatically based on previous week, and are updated once a new week is opened
you can use it the way you like or adapt to your trading strategy
i really use it at extremes and when a divergence is occurring in these zones

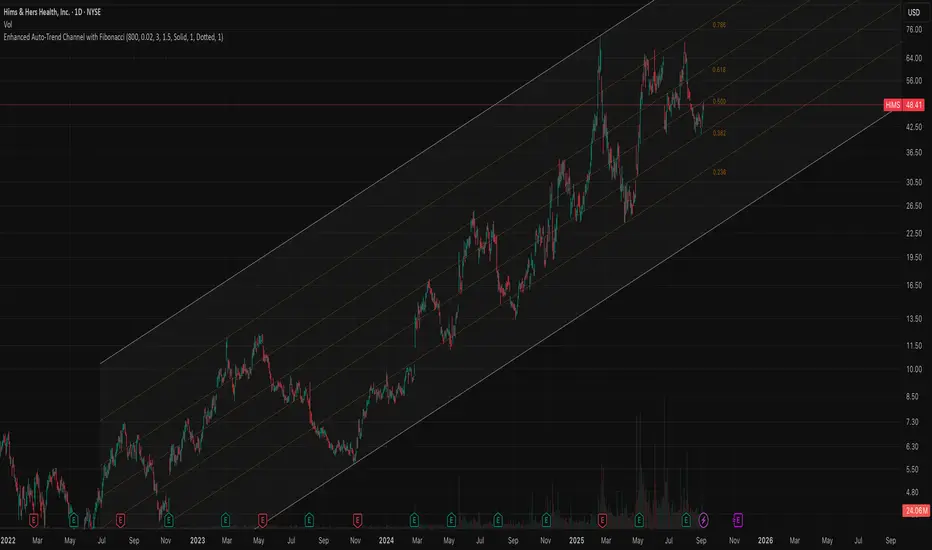
Auto Trend Channel with Fibonacci‼️ PLEASE USE WITH LOG CHART
🟠 Overview
This indicator introduces a novel approach to trend channel construction by implementing a touch-based validation system that ensures channels actually function as dynamic support and resistance levels. Unlike traditional linear regression channels that simply fit a mathematical line through price data, this indicator validates channel effectiveness by measuring how frequently price interacts with the boundaries, creating channels that traders can reliably use for entry and exit decisions.
🟠 Core Idea: Touch-Based Channel Validation
The fundamental problem with standard regression channels is that they often create mathematically correct but practically useless boundaries that price rarely respects. This indicator solves this by introducing a dual-scoring optimization system that evaluates each potential channel based on two critical factors:
Trend Correlation (70% weight): Measures how well prices follow the overall trend direction using Pearson correlation coefficient
Boundary Touch Frequency (30% weight): Counts actual instances where price highs touch the upper channel and lows touch the lower channel
This combination ensures the selected channel not only follows the trend but actively serves as support and resistance.
🟠 Trading Applications
Trend Following
Strong Uptrend: Price consistently bounces off lower channel and Fibonacci levels
Strong Downtrend: Price repeatedly fails at upper channel and Fibonacci resistance
Trend Weakening: Price fails to reach channel extremes or breaks through
Entry Strategies
Channel Bounce Entries: Enter long when price touches lower channel with confirmation; short at upper channel touches
Fibonacci Retracement Entries: Use 38.2% or 61.8% levels for pullback entries in trending markets
Breakout Entries: Trade breakouts when price closes beyond channels with increased volume
🟠 Customization Parameters
Automatic/Manual Period: Choose between intelligent auto-detection or fixed lookback period
Touch Sensitivity (0.1%-10%): Defines how close price must be to count as a boundary touch
Minimum Touches (1-10): Filter threshold for channel validation
Adaptive Deviation: Toggle between calculated or manual deviation multipliers
Divergences v2.4 [LTB][SPTG]Open-source credit & license
Original author: LonesomeTheBlue.
This fork by: sirpipthegreat — with attribution to the original work.
License: Open-source, published under the MPL-2.0 (same license header in the code).
I am publishing this open-source in accordance with TradingView’s Open-source reuse rules.
What’s new:
- Fixes & stability (addresses “historical offset beyond buffer” errors)
- Capped and validated all historical indexing with guarded lookbacks (e.g., min(…, 200) style limits) to prevent referencing data beyond the buffer on shorter histories/thin symbols.
- Refactored highest/lowest bars scans to obey the cap and avoid cumulative overflows on long sessions.
- Added per-bar counters with safety clamps to ensure it never exceeds available history.
- Ensured HTF switching doesn’t create invalid offsets when the higher timeframe compresses history.
Modernization & user control:
- Pine v6 upgrade and re-organization of logic for clarity/performance.
- More predictable tops/bottoms detection.
What it does:
- Detects regular (trend-reversal) and optional hidden (trend-continuation) divergences between price swing tops/bottoms and the selected oscillator(s).
- Computes candidate pivots with a light HTF alignment to reduce micro-noise; validates divergence when oscillator and price move in opposite directions across those pivots.
- Plots colored lines/labels on price to highlight bearish (regular & hidden) and bullish (regular & hidden) patterns.
How to use:
- Choose the oscillator set you trust (start with RSI + MACD).
- Consider confluence (S/R, volume, trend filters). This tool only identifies conditions
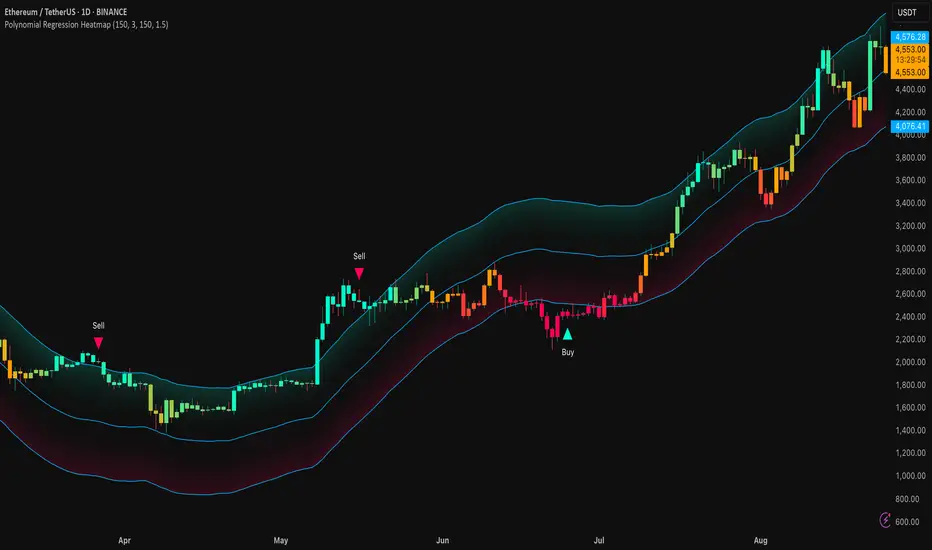
Polynomial Regression HeatmapPolynomial Regression Heatmap – Advanced Trend & Volatility Visualizer
Overview
The Polynomial Regression Heatmap is a sophisticated trading tool designed for traders who require a clear and precise understanding of market trends and volatility. By applying a second-degree polynomial regression to price data, the indicator generates a smooth trend curve, augmented with adaptive volatility bands and a dynamic heatmap. This framework allows users to instantly recognize trend direction, potential reversals, and areas of market strength or weakness, translating complex price action into a visually intuitive map.
Unlike static trend indicators, the Polynomial Regression Heatmap adapts to changing market conditions. Its visual design—including color-coded candles, regression bands, optional polynomial channels, and breakout markers—ensures that price behavior is easy to interpret. This makes it suitable for scalping, swing trading, and longer-term strategies across multiple asset classes.
How It Works
The core of the indicator relies on fitting a second-degree polynomial to a defined lookback period of price data. This regression curve captures the non-linear nature of market movements, revealing the true trajectory of price beyond the distortions of noise or short-term volatility.
Adaptive upper and lower bands are constructed using ATR-based scaling, surrounding the regression line to reflect periods of high and low volatility. When price moves toward or beyond these bands, it signals areas of potential overextension or support/resistance.
The heatmap colors each candle based on its relative position within the bands. Green shades indicate proximity to the upper band, red shades indicate proximity to the lower band, and neutral tones represent mid-range positioning. This continuous gradient visualization provides immediate feedback on trend strength, market balance, and potential turning points.
Optional polynomial channels can be overlaid around the regression curve. These three-line channels are based on regression residuals and a fixed width multiplier, offering additional reference points for analyzing price deviations, trend continuation, and reversion zones.
Signals and Breakouts
The Polynomial Regression Heatmap includes statistical pivot-based signals to highlight actionable price movements:
Buy Signals – A triangular marker appears below the candle when a pivot low occurs below the lower regression band.
Sell Signals – A triangular marker appears above the candle when a pivot high occurs above the upper regression band.
These markers identify significant deviations from the regression curve while accounting for volatility, providing high-quality visual cues for potential entry points.
The indicator ensures clarity by spacing markers vertically using ATR-based calculations, preventing overlap during periods of high volatility. Users can rely on these signals in combination with heatmap intensity and regression slope for contextual confirmation.
Interpretation
Trend Analysis :
The slope of the polynomial regression line represents trend direction. A rising curve indicates bullish bias, a falling curve indicates bearish bias, and a flat curve indicates consolidation.
Steeper slopes suggest stronger momentum, while gradual slopes indicate more moderate trend conditions.
Volatility Assessment :
Band width provides an instant visual measure of market volatility. Narrow bands correspond to low volatility and potential consolidation, whereas wide bands indicate higher volatility and significant price swings.
Heatmap Coloring :
Candle colors visually represent price position within the bands. This allows traders to quickly identify zones of bullish or bearish pressure without performing complex calculations.
Channel Analysis (Optional) :
The polynomial channel defines zones for evaluating potential overextensions or retracements. Price interacting with these lines may suggest areas where mean-reversion or trend continuation is likely.
Breakout Signals :
Buy and Sell markers highlight pivot points relative to the regression and volatility bands. These are statistical signals, not arbitrary triggers, and should be interpreted in context with trend slope, band width, and heatmap intensity.
Strategy Integration
The Polynomial Regression Heatmap supports multiple trading approaches:
Trend Following – Enter trades in the direction of the regression slope while using the heatmap for momentum confirmation.
Pullback Entries – Use breakouts or deviations from the regression bands as low-risk entry points during trend continuation.
Mean Reversion – Price reaching outer channel boundaries can indicate potential reversal or retracement opportunities.
Multi-Timeframe Alignment – Overlay on higher and lower timeframes to filter noise and improve entry timing.
Stop-loss levels can be set just beyond the opposing regression band, while take-profit targets can be informed by the distance between the bands or the curvature of the polynomial line.
Advanced Techniques
For traders seeking greater precision:
Combine the Polynomial Regression Heatmap with volume, momentum, or volatility indicators to validate signals.
Observe the width and slope of the regression bands over time to anticipate expanding or contracting volatility.
Track sequences of breakout signals in conjunction with heatmap intensity for systematic trade management.
Adjusting regression length allows customization for different assets or timeframes, balancing responsiveness and smoothing. The combination of polynomial curve, adaptive bands, heatmap, and optional channels provides a comprehensive statistical framework for informed decision-making.
Inputs and Customization
Regression Length – Determines the number of bars used for polynomial fitting. Shorter lengths increase responsiveness; longer lengths improve smoothing.
Show Bands – Toggle visibility of the ATR-based regression bands.
Show Channel – Enable or disable the polynomial channel overlay.
Color Settings – Customize bullish, bearish, neutral, and accent colors for clarity and visual preference.
All other internal parameters are fixed to ensure consistent statistical behavior and minimize potential misconfiguration.
Why Use Polynomial Regression Heatmap
The Polynomial Regression Heatmap transforms complex price action into a clear, actionable visual framework. By combining non-linear trend mapping, adaptive volatility bands, heatmap visualization, and breakout signals, it provides a multi-dimensional perspective that is both quantitative and intuitive.
This indicator allows traders to focus on execution, interpret market structure at a glance, and evaluate trend strength, overextensions, and potential reversals in real time. Its design is compatible with scalping, swing trading, and long-term strategies, providing a robust tool for disciplined, data-driven trading.
IFVG by Toño# IFVG by Toño - Pine Script Indicator
## Overview
This Pine Script indicator identifies and visualizes **Fair Value Gaps (FVG)** and **Inverted Fair Value Gaps (IFVG)** on trading charts. It provides advanced analysis of price inefficiencies and their subsequent inversions when mitigated.
## Key Features
### 1. Fair Value Gap (FVG) Detection
- **Bullish FVG**: Detected when `low > high ` (gap between current low and high of 2 bars ago)
- **Bearish FVG**: Detected when `high < low ` (gap between current high and low of 2 bars ago)
- Visual representation using colored rectangles (green for bullish, red for bearish)
### 2. Inverted Fair Value Gap (IFVG) Creation
- **IFVG Formation**: When a FVG gets mitigated (price fills the gap with candle body), an IFVG is created
- **Color Inversion**: The IFVG takes the opposite color of the original FVG
- Mitigated bullish FVG → Creates red (bearish) IFVG
- Mitigated bearish FVG → Creates green (bullish) IFVG
- **Mitigation Logic**: Uses only candle body (not wicks) to determine when a FVG is filled
### 3. Customizable Display Options
- **Show Normal FVG**: Toggle visibility of regular Fair Value Gaps
- **Show IFVG**: Toggle visibility of Inverted Fair Value Gaps
- **Smart FVG Display**: Even when "Show Normal FVG" is disabled, FVGs that are part of IFVGs remain visible
- **Extension Control**: Option to extend FVGs until they are mitigated
### 4. IFVG Extension Methods
- **Full Cross Method**: IFVG remains active until price completely crosses through it (including wicks)
- **Number of Bars Method**: IFVG remains active for a specified number of bars (1-100)
### 5. Visual Mitigation Signals
- **Cross Markers**: Shows X-shaped markers when IFVGs are mitigated
- Green cross above bar: Bearish IFVG mitigated
- Red cross below bar: Bullish IFVG mitigated
### 6. Comprehensive Alert System
- **IFVG Formation Alerts**: Notifications when new IFVGs are created
- **IFVG Mitigation Alerts**: Notifications when IFVGs are filled/mitigated
- **Separate Controls**: Individual toggles for bullish and bearish IFVG alerts
## How It Works
### Step-by-Step Process:
1. **FVG Detection**: Script continuously scans for 3-bar patterns that create price gaps
2. **FVG Tracking**: Each FVG is stored with its coordinates, type, and status
3. **Mitigation Monitoring**: Script watches for candle bodies that fill the FVG
4. **IFVG Creation**: Upon mitigation, creates an IFVG with opposite polarity at the same location
5. **IFVG Management**: Tracks and extends IFVGs according to chosen method
6. **Visual Updates**: Dynamically updates colors and visibility based on user settings
## Use Cases
- **Support/Resistance Analysis**: IFVGs often act as strong support/resistance levels
- **Market Structure Understanding**: Helps identify how market inefficiencies get filled and reversed
- **Entry/Exit Timing**: Can be used to time entries around IFVG formations or mitigations
- **Confluence Analysis**: Combine with other technical analysis tools for stronger signals
## Configuration Parameters
- **Colors**: Customizable colors for bullish/bearish FVGs and IFVGs
- **Extension**: Choose how long to display gaps on the chart
- **Alerts**: Full control over notification preferences
- **Visual Clarity**: Options to show/hide different gap types for cleaner charts
## Technical Specifications
- **Pine Script Version**: 5
- **Overlay**: True (displays directly on price chart)
- **Max Boxes**: 500 (supports up to 500 simultaneous gaps)
- **Performance**: Optimized array management for smooth operation
This indicator is particularly valuable for traders who use **Smart Money Concepts (SMC)** and **Inner Circle Trader (ICT)** methodologies, as it provides clear visualization of how institutional order flow creates and fills market inefficiencies.
Meta-LR ForecastThis indicator builds a forward-looking projection from the current bar by combining twelve time-compressed “mini forecasts.” Each forecast is a linear-regression-based outlook whose contribution is adaptively scaled by trend strength (via ADX) and normalized to each timeframe’s own volatility (via that timeframe’s ATR). The result is a 12-segment polyline that starts at the current price and extends one bar at a time into the future (1× through 12× the chart’s timeframe). Alongside the plotted path, the script computes two summary measures:
* Per-TF Bias% — a directional efficiency × R² score for each micro-forecast, expressed as a percent.
* Meta Bias% — the same score, but applied to the final, accumulated 12-step path. It summarizes how coherent and directional the combined projection is.
This tool is an indicator, not a strategy. It does not place orders. Nothing here is trade advice; it is a visual, quantitative framework to help you assess directional bias and trend context across a ladder of timeframe multiples.
The core engine fits a simple least-squares line on a normalized price series for each small forecast horizon and extrapolates one bar forward. That “trend” forecast is paired with its mirror, an “anti-trend” forecast, constructed around the current normalized price. The model then blends between these two wings according to current trend strength as measured by ADX.
ADX is transformed into a weight (w) in using an adaptive band centered on the rolling mean (μ) with width derived from the standard deviation (σ) of ADX over a configurable lookback. When ADX is deeply below the lower band, the weight approaches -1, favoring anti-trend behavior. Inside the flat band, the weight is near zero, producing neutral behavior. Clearly above the upper band, the weight approaches +1, favoring a trend-following stance. The transitions between these regions are linear so the regime shift is smooth rather than abrupt.
You can shape how quickly the model commits to either wing using two exponents. One exponent controls how aggressively positive weights lean into the trend forecast; the other controls how aggressively negative weights lean into the anti-trend forecast. Raising these exponents makes the response more gradual; lowering them makes the shift more decisive. An optional switch can force full anti-trend behavior when ADX registers a deep-low condition far below the lower tail, if you prefer a categorical stance in very flat markets.
A key design choice is volatility normalization. Every micro-forecast is computed in ATR units of its own timeframe. The script fetches that timeframe’s ATR inside each security call and converts normalized outputs back to price with that exact ATR. This avoids scaling higher-timeframe effects by the chart ATR or by square-root time approximations. Using “ATR-true” for each timeframe keeps the cross-timeframe accumulation consistent and dimensionally correct.
Bias% is defined as directional efficiency multiplied by R², expressed as a percent. Directional efficiency captures how much net progress occurred relative to the total path length; R² captures how well the path aligns with a straight line. If price meanders without net progress, efficiency drops; if the variation is well-explained by a line, R² rises. Multiplying the two penalizes choppy, low-signal paths and rewards sustained, coherent motion.
The forward path is built by converting each per-timeframe Bias% into a small ATR-sized delta, then cumulatively adding those deltas to form a 12-step projection. This produces a polyline anchored at the current close and stepping forward one bar per timeframe multiple. Segment color flips by slope, allowing a quick read of the path’s direction and inflection.
Inputs you can tune include:
* Max Regression Length. Upper bound for each micro-forecast’s regression window. Larger values smooth the trend estimate at the cost of responsiveness; smaller values react faster but can add noise.
* Price Source. The price series analyzed (for example, close or typical price).
* ADX Length. Period used for the DMI/ADX calculation.
* ATR Length (normalization). Window used for ATR; this is applied per timeframe inside each security call.
* Band Lookback (for μ, σ). Lookback used to compute the adaptive ADX band statistics. Larger values stabilize the band; smaller values react more quickly.
* Flat half-width (σ). Width of the neutral band on both sides of μ. Wider flats spend more time neutral; narrower flats switch regimes more readily.
* Tail width beyond flat (σ). Distance from the flat band edge to the extreme trend/anti-trend zone. Larger tails create a longer ramp; smaller tails reach extremes sooner.
* Polyline Width. Visual thickness of the plotted segments.
* Negative Wing Aggression (anti-trend). Exponent shaping for negative weights; higher values soften the tilt into mean reversion.
* Positive Wing Aggression (trend). Exponent shaping for positive weights; lower values make trend commitment stronger and sooner.
* Force FULL Anti-Trend at Deep-Low ADX. Optional hard switch for extremely low ADX conditions.
On the chart you will see:
* A 12-segment forward polyline starting from the current close to bar\_index + 1 … +12, with green segments for up-steps and red for down-steps.
* A small label at the latest bar showing Meta Bias% when available, or “n/a” when insufficient data exists.
Interpreting the readouts:
* Trend-following contexts are characterized by ADX above the adaptive upper band, pushing w toward +1. The blended forecast leans toward the regression extrapolation. A strongly positive Meta Bias% in this environment suggests directional alignment across the ladder of timeframes.
* Mean-reversion contexts occur when ADX is well below the lower tail, pushing w toward -1 (or forcing anti-trend if enabled). After a sharp advance, a negative Meta Bias% may indicate the model projects pullback tendencies.
* Neutral contexts occur when ADX sits inside the flat band; w is near zero, the blended forecast remains close to current price, and Meta Bias% tends to hover near zero.
These are analytical cues, not rules. Always corroborate with your broader process, including market structure, time-of-day behavior, liquidity conditions, and risk limits.
Practical usage patterns include:
* Momentum confirmation. Combine a rising Meta Bias% with higher-timeframe structure (such as higher highs and higher lows) to validate continuation setups. Treat the 12th step’s distance as a coarse sense of potential room rather than as a target.
* Fade filtering. If you prefer fading extremes, require ADX to be near or below the lower ramp before acting on counter-moves, and avoid fades when ADX is decisively above the upper band.
* Position planning. Because per-step deltas are ATR-scaled, the path’s vertical extent can be mentally mapped to typical noise for the instrument, informing stop distance choices. The script itself does not compute orders or size.
* Multi-timeframe alignment. Each step corresponds to a clean multiple of your chart timeframe, so the polyline visualizes how successively larger windows bias price, all referenced to the current bar.
House-rules and repainting disclosures:
* Indicator, not strategy. The script does not execute, manage, or suggest orders. It displays computed paths and bias scores for analysis only.
* No performance claims. Past behavior of any measure, including Meta Bias%, does not guarantee future results. There are no assurances of profitability.
* Higher-timeframe updates. Values obtained via security for higher-timeframe series can update intrabar until the higher-timeframe bar closes. The forward path and Meta Bias% may change during formation of a higher-timeframe candle. If you need confirmed higher-timeframe inputs, consider reading the prior higher-timeframe value or acting only after the higher-timeframe close.
* Data sufficiency. The model requires enough history to compute ATR, ADX statistics, and regression windows. On very young charts or illiquid symbols, parts of the readout can be unavailable until sufficient data accumulates.
* Volatility regimes. ATR normalization helps compare across timeframes, but unusual volatility regimes can make the path look deceptively flat or exaggerated. Judge the vertical scale relative to your instrument’s typical ATR.
Tuning tips:
* Stability versus responsiveness. Increase Max Regression Length to steady the micro-forecasts but accept slower response. If you lower it, consider slightly increasing Band Lookback so regime boundaries are not too jumpy.
* Regime bands. Widen the flat half-width to spend more time neutral, which can reduce over-trading tendencies in chop. Shrink the tail width if you want the model to commit to extremes sooner, at the cost of more false swings.
* Wing shaping. If anti-trend behavior feels too abrupt at low ADX, raise the negative wing exponent. If you want trend bias to kick in more decisively at high ADX, lower the positive wing exponent. Small changes have large effects.
* Forced anti-trend. Enable the deep-low option only if you explicitly want a categorical “markets are flat, fade moves” policy. Many users prefer leaving it off to keep regime decisions continuous.
Troubleshooting:
* Nothing plots or the label shows “n/a.” Ensure the chart has enough history for the ADX band statistics, ATR, and the regression windows. Exotic or illiquid symbols with missing data may starve the higher-timeframe computations. Try a more liquid market or a higher timeframe.
* Path flickers or shifts during the bar. This is expected when any higher-timeframe input is still forming. Wait for the higher-timeframe close for fully confirmed behavior, or modify the code to read prior values from the higher timeframe.
* Polyline looks too flat or too steep. Check the chart’s vertical scale and recent ATR regime. Adjust Max Regression Length, the wing exponents, or the band widths to suit the instrument.
Integration ideas for manual workflows:
* Confluence checklist. Use Meta Bias% as one of several independent checks, alongside structure, session context, and event risk. Act only when multiple cues align.
* Stop and target thinking. Because deltas are ATR-scaled at each timeframe, benchmark your proposed stops and targets against the forward steps’ magnitude. Stops that are much tighter than the prevailing ATR often sit inside normal noise.
* Session context. Consider session hours and microstructure. The same ADX value can imply different tradeability in different sessions, particularly in index futures and FX.
This indicator deliberately avoids:
* Fixed thresholds for buy or sell decisions. Markets vary and fixed numbers invite overfitting. Decide what constitutes “high enough” Meta Bias% for your market and timeframe.
* Automatic risk sizing. Proper sizing depends on account parameters, instrument specifications, and personal risk tolerance. Keep that decision in your risk plan, not in a visual bias tool.
* Claims of edge. These measures summarize path geometry and trend context; they do not ensure a tradable edge on their own.
Summary of how to think about the output:
* The script builds a 12-step forward path by stacking linear-regression micro-forecasts across increasing multiples of the chart timeframe.
* Each micro-forecast is blended between trend and anti-trend using an adaptive ADX band with separate aggression controls for positive and negative regimes.
* All computations are done in ATR-true units for each timeframe before reconversion to price, ensuring dimensional consistency when accumulating steps.
* Bias% (per-timeframe and Meta) condenses directional efficiency and trend fidelity into a compact score.
* The output is designed to serve as an analytical overlay that helps assess whether conditions look trend-friendly, fade-friendly, or neutral, while acknowledging higher-timeframe update behavior and avoiding prescriptive trade rules.
Use this tool as one component within a disciplined process that includes independent confirmation, event awareness, and robust risk management.

Kaos CHoCH M15 – Confirm + BOS H4 Bias (no repinta)Marca choch en dirección del Bias de H4 para seguir con la tendencia.
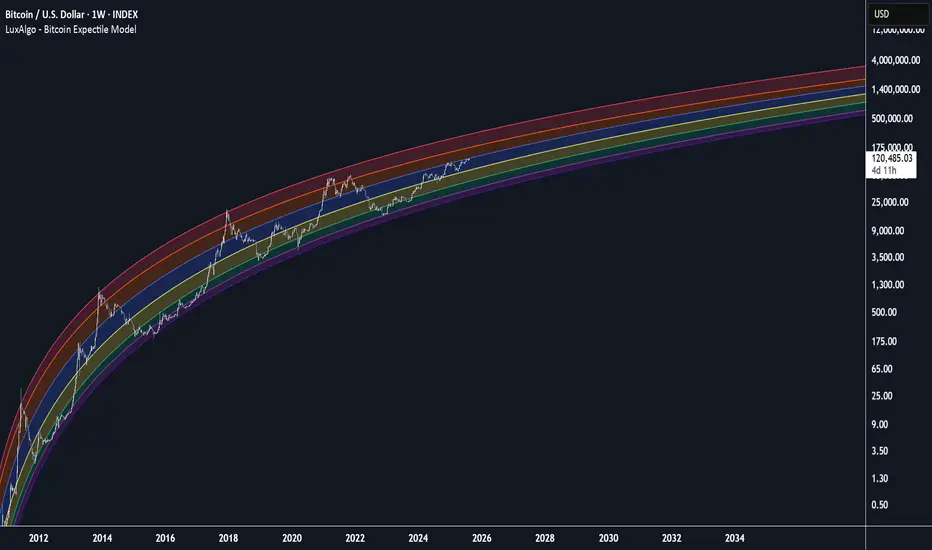
Bitcoin Expectile Model [LuxAlgo]The Bitcoin Expectile Model is a novel approach to forecasting Bitcoin, inspired by the popular Bitcoin Quantile Model by PlanC. By fitting multiple Expectile regressions to the price, we highlight zones of corrections or accumulations throughout the Bitcoin price evolution.
While we strongly recommend using this model with the Bitcoin All Time History Index INDEX:BTCUSD on the 3 days or weekly timeframe using a logarithmic scale, this model can be applied to any asset using the daily timeframe or superior.
Please note that here on TradingView, this model was solely designed to be used on the Bitcoin 1W chart, however, it can be experimented on other assets or timeframes if of interest.
🔶 USAGE
The Bitcoin Expectile Model can be applied similarly to models used for Bitcoin, highlighting lower areas of possible accumulation (support) and higher areas that allow for the anticipation of potential corrections (resistance).
By default, this model fits 7 individual Expectiles Log-Log Regressions to the price, each with their respective expectile ( tau ) values (here multiplied by 100 for the user's convenience). Higher tau values will return a fit closer to the higher highs made by the price of the asset, while lower ones will return fits closer to the lower prices observed over time.
Each zone is color-coded and has a specific interpretation. The green zone is a buy zone for long-term investing, purple is an anomaly zone for market bottoms that over-extend, while red is considered the distribution zone.
The fits can be extrapolated, helping to chart a course for the possible evolution of Bitcoin prices. Users can select the end of the forecast as a date using the "Forecast End" setting.
While the model is made for Bitcoin using a log scale, other assets showing a tendency to have a trend evolving in a single direction can be used. See the chart above on QQQ weekly using a linear scale as an example.
The Start Date can also allow fitting the model more locally, rather than over a large range of prices. This can be useful to identify potential shorter-term support/resistance areas.
🔶 DETAILS
🔹 On Quantile and Expectile Regressions
Quantile and Expectile regressions are similar; both return extremities that can be used to locate and predict prices where tops/bottoms could be more likely to occur.
The main difference lies in what we are trying to minimize, which, for Quantile regression, is commonly known as Quantile loss (or pinball loss), and for Expectile regression, simply Expectile loss.
You may refer to external material to go more in-depth about these loss functions; however, while they are similar and involve weighting specific prices more than others relative to our parameter tau, Quantile regression involves minimizing a weighted mean absolute error, while Expectile regression minimizes a weighted squared error.
The squared error here allows us to compute Expectile regression more easily compared to Quantile regression, using Iteratively reweighted least squares. For Quantile regression, a more elaborate method is needed.
In terms of comparison, Quantile regression is more robust, and easier to interpret, with quantiles being related to specific probabilities involving the underlying cumulative distribution function of the dataset; on the other expectiles are harder to interpret.
🔹 Trimming & Alterations
It is common to observe certain models ignoring very early Bitcoin price ranges. By default, we start our fit at the date 2010-07-16 to align with existing models.
By default, the model uses the number of time units (days, weeks...etc) elapsed since the beginning of history + 1 (to avoid NaN with log) as independent variable, however the Bitcoin All Time History Index INDEX:BTCUSD do not include the genesis block, as such users can correct for this by enabling the "Correct for Genesis block" setting, which will add the amount of missed bars from the Genesis block to the start oh the chart history.
🔶 SETTINGS
Start Date: Starting interval of the dataset used for the fit.
Correct for genesis block: When enabled, offset the X axis by the number of bars between the Bitcoin genesis block time and the chart starting time.
🔹 Expectiles
Toggle: Enable fit for the specified expectile. Disabling one fit will make the script faster to compute.
Expectile: Expectile (tau) value multiplied by 100 used for the fit. Higher values will produce fits that are located near price tops.
🔹 Forecast
Forecast End: Time at which the forecast stops.
🔹 Model Fit
Iterations Number: Number of iterations performed during the reweighted least squares process, with lower values leading to less accurate fits, while higher values will take more time to compute.

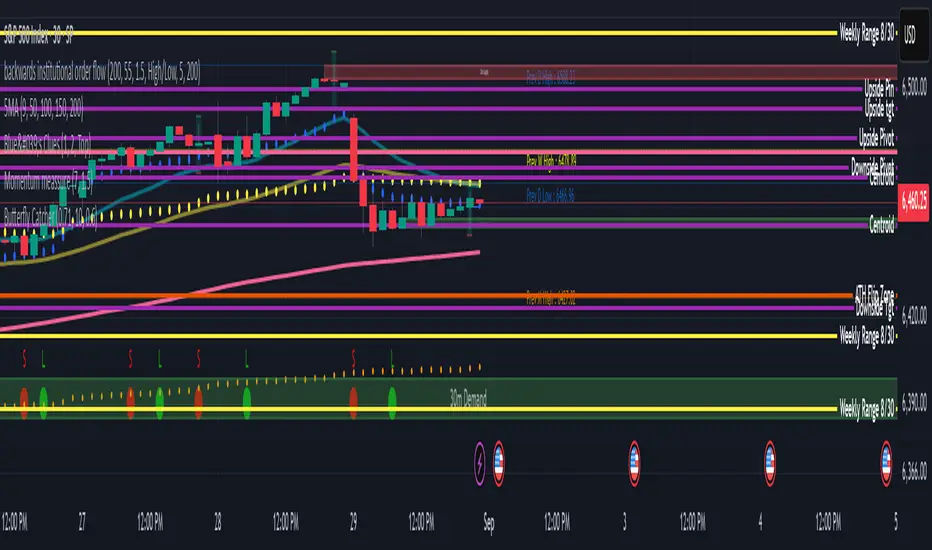
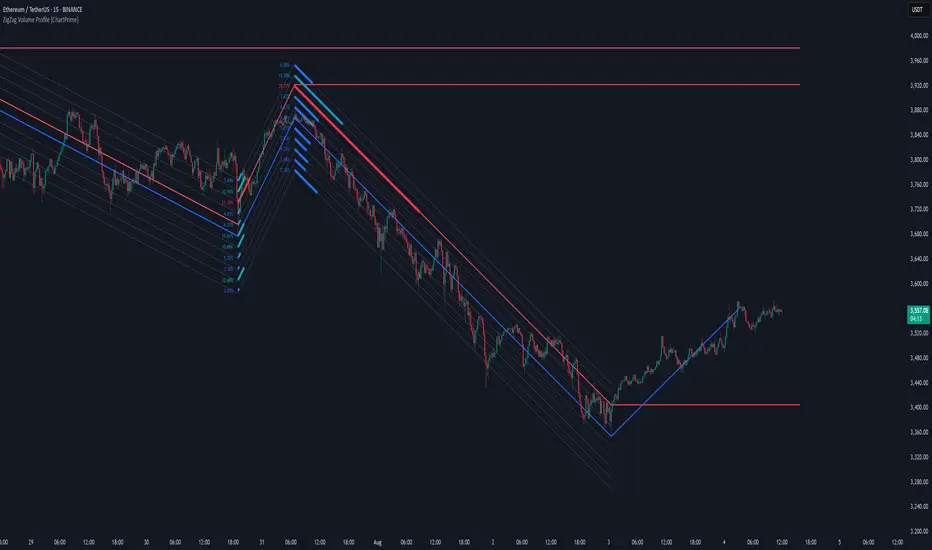
ZigZag Volume Profile [ChartPrime]⯁ OVERVIEW
ZigZag Volume Profile combines swing structure with volume analytics by plotting a ZigZag of major price swings and overlaying a detailed volume profile around each swing. At the end of each swing, it highlights the Point of Control (POC) — the price level with the highest traded volume — and extends it forward to identify key areas of potential support or resistance.
⯁ KEY FEATURES
ZigZag Swing Detection:
Automatically detects swing highs and lows based on a user-defined length, creating clean visual segments of market structure.
These segments act as boundaries for volume profile calculations.
swingHigh = ta.highest(swingLength)
swingLow = ta.lowest(swingLength)
ZigZag Channel Visualization:
The ZigZag structure is connected with sloped lines, forming a visual “channel” of the price movement.
The ZigZag can optionally, scaled by ATR.
Volume Profile Around Each Swing:
For every completed swing (high to low or low to high), the indicator constructs a full volume profile using user-defined bin counts.
It scans volume across price levels in the swing and plots histogram-style bins using a gradient color to indicate volume magnitude.
Dynamic Bin Width and Slope Adjustment:
Bins are distributed across a vertical ATR-based range, and their width is adjusted based on the percentage of total swing volume.
The volume fill direction is adapted to the swing’s slope for visually aligned plotting.
POC Detection and Extension:
The highest volume bin in each swing is identified as the Point of Control (POC).
This level is plotted with a thicker line and extended horizontally into the future as a key reaction level.
Automatic POC Expiry on Price Interaction:
POC lines are continuously extended unless breached by price.
When price crosses the POC level, the extension is terminated — signaling that the level may have been absorbed.
Clean Volume Bin Visualization:
Bin colors range from green (low volume) to blue (higher volume), with the POC always marked in red by default for easy identification.
Volume percentages are optionally labeled at each bin level.
Flexible Swing Profile Parameters:
Users can control:
Number of volume bins
Bin width
Channel width (ATR factor)
Visibility of the swing channel or POC lines
Efficient Memory Handling:
Old POC lines and volume profiles are automatically removed from memory after a threshold to keep charts clean and performant.
⯁ USAGE
Use ZigZag swings to define market structure visually.
Analyze volume profile around each swing to understand where most trading activity occurred.
Use POC extensions as dynamic support/resistance zones for entries, stops, or take-profits.
Watch for price interaction with extended POC lines — breaks may suggest absorbed liquidity or breakout potential.
Use the ATR-based channel width to adapt profiles based on market volatility.
⯁ CONCLUSION
ZigZag Volume Profile offers a powerful fusion of structure and volume. By plotting detailed volume profiles over each price swing and extending the POC as actionable S/R levels, this tool provides deep insight into market participation zones — giving traders a tactical edge in both ranging and trending environments.
Market Extension Quantifier SniperIt's a combination of ATR, Moving Average, Bollinger Bands and RSI. And the idea is to find a very extended move which creates a probability that the market is due to a reversion.

Canonical Momenta Indicator [T1][T69]📌 Overview
The Canonical Momenta Indicator models trend pressure using a Lagrangian-based momentum engine combined with reflexivity theory to detect bursts in price movement influenced by herd behavior and volume acceleration.
🧠 Features
Lagrangian-based kinetic model combining velocity and acceleration
Reflexivity burst detection with directional scoring
Adaptive momentum-weighted output (adaptiveCMI)
Buy 🐋 / Sell 🐻 labels when reflexivity confirms direction
Fully parameterized for customization
⚙️ How to Use
This indicator helps traders:
Detect reflexive bursts in market activity driven by sharp price movement + volume spikes
Capture herd-driven directional moves early.
Gauge market pressure using a kinetic-potential energy model.
Suggested signals:
🐋 Reflexive Up: Strong bullish momentum spike confirmed by volume and positive lagrangian pressure
🐻 Reflexive Down: Strong bearish dump confirmed by volume and negative lagrangian burst
🔧 Configuration
MA Lookback Length - Smoothing for baseline price & energy calculation
Reflexivity Momentum Threshold - Price momentum trigger for burst detection
Reflexivity Lookback - Period over which bursts are counted
Reflexivity Window - Minimum burst sum to trigger signal label
Volume Spike Threshold - % above average volume to qualify as burst
📊 Behavior Description
The indicator computes a Lagrangian energy:
Kinetic Energy = (velocity² + 0.5 * acceleration²)
Potential Energy = deviation from moving average (distance²)
Lagrangian = Potential − Kinetic (higher = overextension)
Then, reflexive bursts are triggered when:
Price is rising or falling over short window (burstMvmnt)
Volume is above average by a user-defined multiple
Each bar gets a burst score:
+1 for up-burst
−1 for down-burst
0 otherwise
⚠️ Risk Profile Based on Lookback Settings
Risk Level | Description | Recommended Lookback
🟥 High | Extremely sensitive to bursts, prone to false signals | 7–10
🟨 Moderate | Balanced reflexivity with trend confirmation | 11–20
🟩 Low | Filters out most noise, slower to react | 21+
🧪 Advanced Tips
Combine with moving average slope for trend filtering
Use divergence between adaptiveCMI and price to detect exhaustion
Works well in crypto, commodities, and volatile assets
⚠️ Limitations
Sensitive to high volatility noise if volMult is too low
Designed for higher timeframes (1H, 4H, Daily) for reliability
Doesn’t confirm direction in sideways markets — pair with other filters
📝 Disclaimer
This tool is provided for educational and informational purposes. Always do your own backtesting and use proper risk management.

Linear Regression Log Channel with 3 Standard Deviations, AlertsThis indicator plots a logarithmic linear regression trendline starting from a user-defined date, along with ±1, ±2, and ±3 standard deviation bands. It is designed to help you visualize long-term price trends and statistically significant deviations.
Features:
• Log-scale linear regression line based on price since the selected start date
• Upper and lower bands at 1σ, 2σ, and 3σ, with the 3σ bands dashed for emphasis
• Optional filled channels between deviation bands
• Dynamic label showing:
• Distance from regression (in %)
• Distance in standard deviations (σ)
• Current price and regression value
• Estimated probability (assuming normal distribution) that the price continues moving further in its current direction
• Built-in alerts when price crosses the regression line or any of the deviation bands
This tool is useful for:
• Identifying mean-reversion setups or stretched trends
• Estimating likelihood of further directional movement
• Spotting statistically rare price conditions (e.g., >2σ or >3σ)
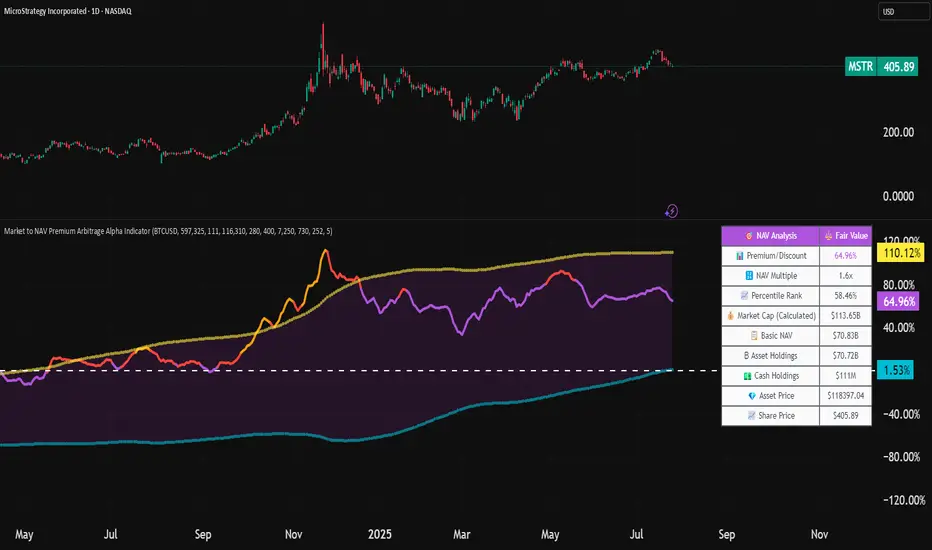
Market to NAV Premium Arbitrage Alpha IndicatorBitcoin treasury companies such as Microstrategy are known for trading at significant premiums. but how big exactly is the premium? And how can we measure it in real time?
I developed this quantitative tool to identify statistical mispricings between market capitalization and net asset value (NAV), specifically designed for arbitrage strategies and alpha generation in Bitcoin-holding companies, such as MicroStrategy or Sharplink Gaming, or SPACs used primarily to hold cryptocurrencies, Bitcoin ETFs, and other NAV-based instruments. It can probably also be used in certain spin-offs.
KEY FEATURES:
✅ Real-time Premium/Discount Calculation
• Automatically retrieves market cap data from TradingView
• Calculates precise NAV based on underlying asset holdings (for example Bitcoin)
• Formula: (Market Cap - NAV) / NAV × 100
✅ Statistical Analysis
• Historical percentile rankings (customizable lookback period)
• Standard deviation bands (2σ) for extreme value detection (close to these values might be seen as interesting points to short or go long)
• Smoothing period to reduce noise
✅ Multi-Source Market Cap Detection
• You can add the ticker of the NAV asset, but if necessary, you can also put it manually. Priority system: TradingView data → Calculated → Manual override
✅ Advanced NAV Modeling
• Basic NAV: Asset holdings + cash.
• Adjusted NAV: Includes software business value, debt, preferred shares. If the company has a lot of this kind of intrinsic value, put it in the "cash" field
• Support for any underlying asset (BTC, ETH, etc.)
TRADING APPLICATIONS:
🎯 Pairs Trading Signals
• Long/Short opportunities when premium reaches statistical extremes
• Mean reversion strategies based on historical ranges
• Risk-adjusted position sizing using percentile ranks
🎯 Arbitrage Detection
• Identifies when market pricing significantly deviates from fair value
• Quantifies the magnitude of mispricing for profit potential
• Historical context for timing entry/exit points
CONFIGURATION OPTIONS:
• Underlying Asset: Any symbol (default: COINBASE:BTCUSD) NEEDS MANUAL INPUT
• Asset Quantity: Precise holdings amount (for example, how much BTC does the company currently hold). NEEDS MANUAL INPUT
• Cash Holdings: Additional liquid assets. NEEDS MANUAL INPUT
• Market Cap Mode: Auto-detect, calculated, or manual
• Advanced Adjustments: Business value, debt, preferred shares
• Display Settings: Lookback period, smoothing, custom colors
IT CAN BE USED BY:
• Quantitative traders focused on statistical arbitrage
• Institutional investors monitoring NAV-based instruments
• Bitcoin ETF and MSTR traders seeking alpha generation
• Risk managers tracking premium/discount exposures
• Academic researchers studying market efficiency (as you can see, markets are not efficient 😉)
20-Day SMA BIAS%20-day Bias is a commonly used indicator in technical analysis. It is used to measure the gap between the stock price and its 20-day moving average to determine whether the stock price deviates from the normal state and whether there is an overbought or oversold phenomenon.
How to calculate the 20-day deviation value:
The calculation formula of the deviation rate is: ((closing price of the day - 20-day moving average price) / 20-day moving average price) * 100%.
Interpretation of 20-day deviation value:
Positive deviation rate:
Indicates that the stock price is higher than the 20-day moving average, which means that the stock price is high and may face correction pressure.
Negative deviation rate:
Indicates that the stock price is lower than the 20-day moving average, which means that the stock price is low and there may be a rebound opportunity.
Absolute value of the deviation rate:
The larger the absolute value, the higher the deviation of the stock price, and the higher the degree of overbought or oversold.
Apply the deviation rate to determine the buying and selling opportunities:
Positive deviation rate is too large:
When the positive deviation rate of the stock price from the 20-day moving average is too large, and the stock price is already at a high level, this may be a sell signal.
Negative deviation rate is too large:
When the negative deviation rate of the stock price from the 20-day moving average is too large, and the stock price is already at a low level, this may be a buy signal.
Stock price fluctuates around the moving average:
Stock price usually fluctuates around the moving average and adjusts after over-rising or over-falling.
Practical operation suggestions:
The standards of the market and individual stocks are different:
When the positive and negative deviation rate of the market and the quarterly line is greater than 5%, there is a greater chance of correction; large-cap stocks are between 5% and 10%; small and medium-sized stocks may be above 15% to 20%.
Combined with other indicators:
The deviation rate is only one of the technical analysis indicators. It is recommended to combine it with other indicators, such as KD indicators, RSI, etc., to make a comprehensive judgment and improve accuracy.
Reference to historical experience:
You can refer to the situation where the deviation rate of the stock was too large in the past to determine whether the current deviation rate is also too large.
Summary:
The 20-day deviation value is an indicator to determine whether the stock price is overbought or oversold, which can help investors determine the timing of buying and selling, but it needs to be combined with other indicators and historical data, and adjusted according to market conditions.
